9/10/18
Here are some notes to help seed our discussion for this week's meetings.
Here's how I see the data organization in IODA:

The Record is there primarily to help avoid MPI distribution breaking up groupings that need to stay intact. A particular sounding, or all channels of an instrument are candidates for a Record.
Some design goals for IODA that provide context for this discussion are:
- Solidify the interface
- This will allow us to modify the implementation without thrashing the users of the interface.
- Move toward an SQL-like databse
- Start with simple Fortran structures (eg., arrays)
- Move to C++ structures
- Move to a database (ODB, something else?)
IODA Interface
As a first stab at the interface for IODA, I've organized it into three "views". One for each of the Record, Meta Data and Obs Data as shown above.
The Record interface appears as a list, that contains record id's such as Station ID or Flight ID.
Rec ID 1 Rec ID 2 Rec ID 3 ... The Meta Data interface appears as a 2D table
Lat Lon Time Level ... Loc 1 Loc 2 Loc 3 ... - Rows hold data values, and the size of this dimension corresponds to the number of locations
- Columns are the variables (Lat, Lon, ...)
- Lat, Lon, Time correspond to a Locations object
- Level is also used for location when obs data are points
- Can have additional variables per obs type such as Scan Angle, Scan Position, etc. for Radiance obs type
The Obs Data interface appears as a 3D table
T Q U V ... ObsValue ObsError ObsQc O minus A O minus B ... (not showing depth dimension - goes into the page)
- Rows are objects that are used in the DA system
- Eg., ObsValue is the y vector
- Columns are variables
- For satellite, the individual channels are variables
- Third dimension (depth) holds data values
- Size corresponds to the number of locations
- Size corresponds to the number of locations
- Rows are objects that are used in the DA system
- API
- Access to the Record table
- GetRdata(RecVector)
- PutRdata(RecVector)
- ReadRdata(FileName)
- WriteRdata(FileName)
- Access to the Meta Data table
- GetLocs(Locations)
- GetMdata(MdataVector, col)
- PutMdata(MdataVector, col)
- ReadMdata(FileName, col)
- WriteMdata(FileName, col)
- Access to the Obs Data table
- GetOdata(ObsVector, row, col)
- PutOdata(ObsVector, row, col)
- ReadOdata(ObsVector, row, col)
- WriteOdata(ObsVector, row, col)
- The "Get/Put" methods are for memory-memory transfers
- The Put method would create a new row or column if it did not exist at that point
- The "Read/Write" methods are for memory-file transfers
- The actual read of the file goes in the ObsSpace constructor
- The actual write of the file goes in the ObsSpace destructor
- The above two may mean that the Read/Write methods are private and only used by IODA to build/destroy ObsSpace objects
- The "row" and "col" arguments could be optional where the default would be all variables
- The "row" and "col" arguments could accept regular expressions, or a list
- Access to the Record table
First stage implementation (Fortran structures)
Create three structures corresponding to the three interface views (Record, Meta Data, Obs Data).
- Record ID list
- 1D array
- Size = nrecs
- Meta data table
- 2D array OR a linked list (variables) of 1D arrays (nlocs)
- The linked list would make it easy to adjust for different sets of variables (according to obs type)
- Size (number of rows) = nlocs
- Obs Data table
- 3D array OR linked list of 2D arrays (variables in the columns and obs data in the depth dimension)
- The linked list makes it easy to add new rows such a "O minus A"
- Size of column dimension = nvars
- Size of depth dimension = nlocs
Associations
- The indices along the rows in the Meta Data table (nlocs) correspond to the indices along the depth dimension in the Obs Data table (nlocs).
- Perhaps the way to tie in the Record information is to create a hidden column (Record Number) in the Meta Data table that contains the indices of the associated record. This should be sufficient to be able to pull out the sections of the Obs Data and Meta Data when doing the MPI distribution.
Bookkeeping quantities
- nrecs
- Number of unique records
- Size of a RecVector object
- Used for MPI distribution
- nlocs
- Number of unique locations
- Size of a locations object or MdataVector object
- nvars
- Number of variables in the ObsData table
- Size of the depth dimension in the ObsData table
- nobs
- Size of an ObsVector object
- Equal to nvars * nlocs
Missing values
- Not all locations have all variables (t,q,u,v) for radiosonde and aircraft
- Run-time QC can create missing values (ie, throw out some obs)
- Need to be careful with the method we chose to handle missing values in regard to that method's impact on performance
9/17/18
Last week we decided to take a look at Boost MultiIndex as a possible first stage implementation. This is a header-only extension that allows one to define an arbitrary C structure and then be able to attach indexing to it for storing multiple items and enabling fast access to those items.
Two possible alternatives to MultiIndex are Redis and SQLite. These are both in-memory database implementations that could bring us closer to the SQL-like access that we want, but they incur more overhead than MultiIndex.
Both Redis and SQLite have C++ interfaces, and they both work with their own file formats. We would have to translate netcdf and ODB2 files into Redis or SQLite files, but both packages provide the file I/O routines (to their file formats). In addition to a new file format, Redis also requires a server process to be running where the C++ interface is used by a client (IODA) to access the database. The Redis download from the Redis website is the sever code, and you need to go to a third party source for the client code. There is one in github called bredis which uses Boost ASIO (asynchronous I/O, which is header-only) to do the communication to the server process.
The in-memory aspect of both Redis and SQLite, I believe, is that the data is read into memory from the file and then all access is operated on the memory image which increases performance, but then you are limited to how big of memory image you can create during execution by the operating system.
In my opinion, Redis seems too messy. You have to compile code from two sources (server from Redis website, client from another source), and you have to have server processes running alongside the JEDI process.
SQLite seems to have promise for a longer term solution since it would give us the SQL command interface that we would like to have.
MultiIndex seems promising for an initial implementation. For code development, it is much simpler than Redis or SQLite and we should be able to have a solution in place much faster as a result.
Schematic of Initial IODA Implementation
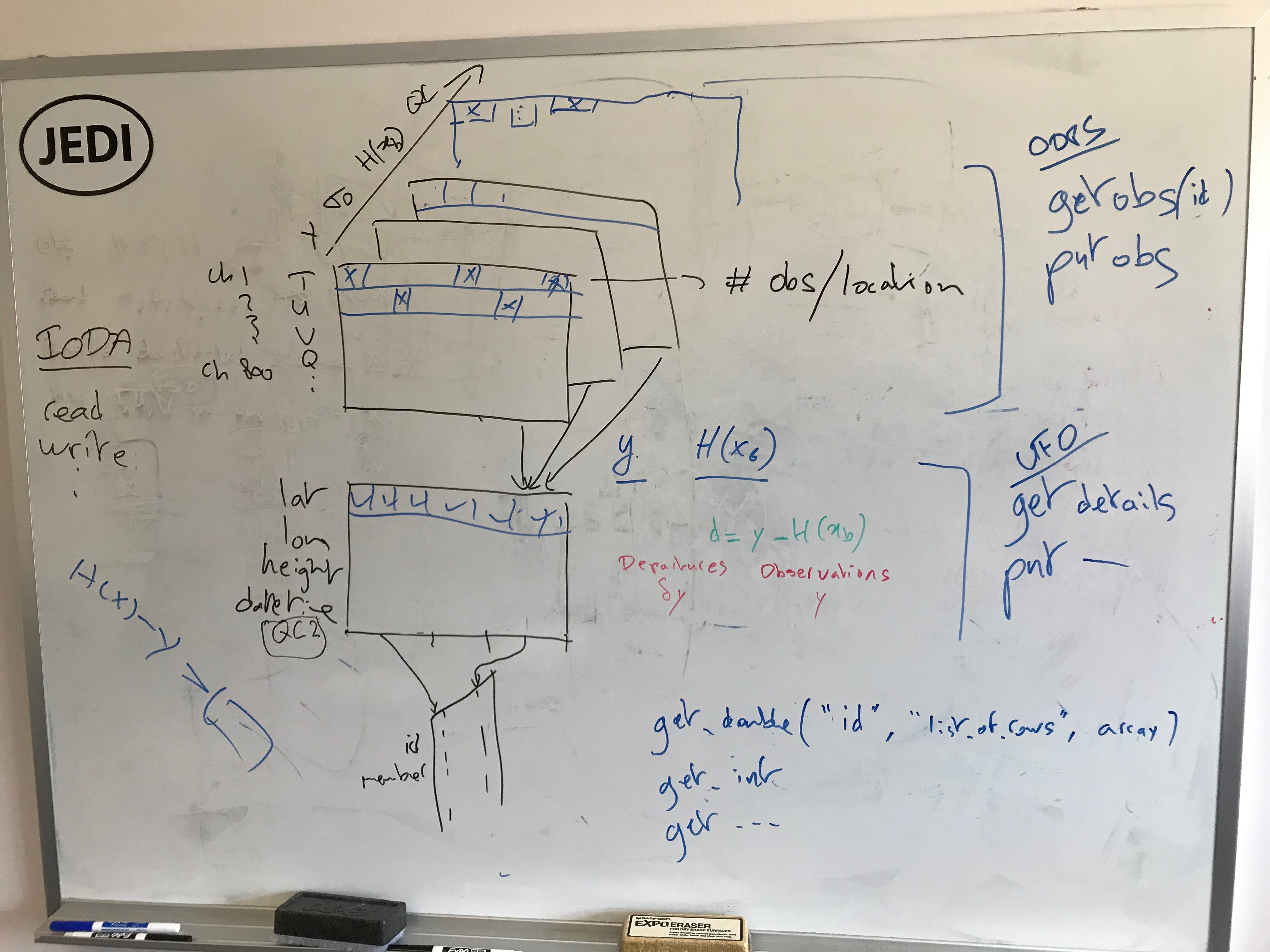
The top shows how observation data are stored. Call this piece ObsData.
The bottom shows how meta data are stored. Call this piece MetaData.
The right side (blue) shows the interface to other pieces of JEDI
- C++ interface only to OOPS (top right side)
- C++ and Fortran interfaces to UFO (middle right side)
The pages in ObsData are similar to the page in MetaData. These have locations along their x-axes, and variables along their y-axes. The MetaData page doesn't fit into the ObsData scheme since it contains a different set of variables (y-axis).
The handling of missing values needs to be done carefully. We could use the QC page to enter a code that represents "missing", but then what if an actual QC code from an obs file collides with the "missing" code. Perhaps we should use a separate page for marking missing values. The obs vector operations will need access to the "missing" marks to do their methods correctly.
Initial Implementation using MultiIndex
The basic building block would look like the following struct example. The storage is a collection of 1D arrays (vectors) that hold values for all locations for one variable.
struct Variable {
// index keys
std::string ObsGroup; // ObsValue, ObsErr, HofX, QC, etc.
std::string VarName; // T, Q, U, V, etc.
// data
std::unique_ptr(T [])& VarData; // 1D array, nlocs long
}
The above example is for the ObsData section. It provides two keys so that the data can be accessed by observation group (ObsValue, ObsError, QC, HofX, etc.) or by variable name (T, Q, U, V, etc.) or by both. The MetaData section would only need the variable name key.
Perhaps we could use classes where the data members hold the keys and data vector. Then we could form the MetaData table from a base class that has the VarName key and VarData vector, and form the ObsData table from a derived class that adds on the ObsGroup key.
Schematically, the memory for ObsData would look like:
