From 20-22 UTC on 8 April, the wind direction held steady, at all levels, at ~ 340-350 deg.
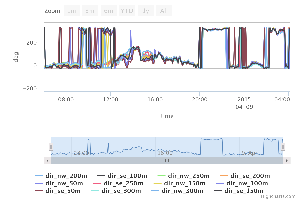
Recall that the NW booms point to 334 deg and the SE booms point to 154 deg.

This flow condition results in a prolonged and distinct tower wake (or mast effect) on the sonics on the SE boom. Wind speeds at the SE booms during this time period are 4-5 ms-1 slower than those measured on the NW booms!

This is a perfect example of mast effects for our classes!

Sensor status:
T: ok
RH: ok
Ifan: ok
spd: ok
P: ok
co2/h2o: ok
csat u,v,w: ok
csat ldiag: "ldiag.nw.250m" "ldiag.nw.300m" "ldiag.se.300m" were all flagged from ~3:00 to 8:30 this morning
soils: ok aside from Qsoil
Wetness: ok
Rsw/Rlw/Rpile: ok
Voltages: ok
sstat outputs: ok, ok (uptime of 2 hr 21 min @ bao)
Sensor status: Note: "Qsoil.ehs" is returning bad data; "Tsoil.0.6cm.ehs" from 9:45 to 11:40 is NA
T: ok
RH: ok
Ifan: ok
spd: ok
P: ok
co2/h2o: ok
csat u,v,w: ok
csat ldiag: ok
soils: "Qsoil.ehs" is returning bad data; "Tsoil.0.6cm.ehs" from 9:45 to 11:40 is NA
Wetness: ok
Rsw/Rlw/Rpile: ok
Voltages: ok
sstat outputs: ok, ok
Sensor status:
T: ok
RH: ok
Ifan: ok
spd: missing spd.5m.bao from 16:40 to 22:30 during moisture event; also, a couple NA's at nw.250m, nw.300m, se.200m
P: ok
co2/h2o: wet but recovered. h2o.5m.bao is a bit lower than it was before the wetness event
csat u,v,w: same as 'spd'
csat ldiag: ok now
soils: Qsoil.ehs has lots of NA data
Wetness: ok
Rsw/Rlw/Rpile: ok
Voltages: ok
sstat outputs: ok, ok

I just noticed that 4 days ago, Tsoil.0.6cm.ehs revived itself, after being offscale since almost the beginning of the project!
In prep for a post-mortem on this project, I wanted to start a page of issues that have occurred:
| Issue | Action Taken | Future Actions |
|---|---|---|
| USB sticks died (all? were purple 8G Transcend) | Switched to Pocketec, Compact Flash, New stick | Replace all sticks with new ones recently purchased |
| GPS timing odd | Widened range of acceptable time lag | Upgrade software on all receivers (3.0-3.7 -> 3.9) |
| 200m DSM needed 150m GPS, but it died | Changed to use 250m? GPS | None? |
| Qsoil reading 0x8000 | none | Fix Check connector at tear-down |
| CSAT3 broken upon installation | Repaired at CSI – bad coax cable in head/box | Unknown - new handling procedure? |
| XBee mote not reliable over 3m distance | Changed to serial mote (tried changing power) | Change to all Bluetooth motes? |
| TRH went to large values | eio power cycle | Unknown |
| TRH fan controller died | Replaced | Check; see if systematic issue for all |
| TRH sensor died | None yet | Improve rain vulnerability? Lightning issue? |
| Lost data connection when eol-rt-data changed | eol-rt-data configuration restored crontab script fixed | SIG checks with Gordon (he tells them when using?) SIG avoids "snapshots" |
| Odd Gsoil at ehs | none | Don't install in darkhorse shadow! |
| EC150 bad data for a week | Cleaned bird scat | Install bird diverters? |
| tsoil.bao mote data intermittent | none; came back | Unknown |
| Mast issues: guy wires; winch; clamp positions; tight nubs | Various in-field adjustments | Systematically check each component for all masts |
| AC powering failed (probably loose connections) | Changed to solar power | Test this option (needed in future) |
| Picklefork Tsoil died (then revived!) | none (had installed duplicate picklefork) | New picklefork design |
| Picklefork completely died (bao) | none | Diagnose Create new picklefork probe (in process) |
| EC150 data garbled on ttyS4 at bao, OK on ttyS4 at ehs | Moved to Emerald serial port on bao | Diagnose. Seems to be a rs422 signal level or termination problem |
DSM networking didn't come up after power drop happened to 150m and 300m | Manually switched off/on | Add battery or ultra cap to main power line? Identify network interface weakness? |
| Mote communications failed on bao Tsoil | Enabled XBee watchdog | Change to Bluetooth Enable all watchdogs New whip antenna location? (birds/wind knock down) |
| New Tirga fan died | Replaced | Better rain protection? |
| New Tirga has radiation error | Installed double-shield | Might be acceptable now |
TRH at 300m has been reporting bad T and RH since about 15:20 today (April 1, no fooling):
rs 5
TRH3 166.68 222.66 29 0 5364 983 92\r\n
TRH3 166.68 223.29 28 0 5364 981 88\r\n
TRH3 166.68 223.60 28 0 5364 980 89\r\n
TRH3 166.68 223.60 29 0 5364 980 92\r\n
Power cycled it with
eio 5 0
eio 5 1
which brought it back:
rs 5
...
TRH3 13.55 29.97 30 0 1339 61 94\r\n
TRH3 13.55 29.97 29 0 1339 61 90\r\n
TRH3 13.50 29.97 30 0 1338 61 94\r\n
Sensor status:
T: ok
RH: ok
Ifan: ok
spd: ok
P: ok
co2/h2o: ok
csat u,v,w: ok
csat ldiag: couple flags
Tsoil: ok
Wetness: ok
Rsw/Rlw/Rpile: ok
Voltages: ok
sstat outputs: ok, ok
The GPS on 100m seems to be acting weird. It has signal lock, currently slowing 9 or 10 satellites:
rs G
connecting to inet:localhost.localdomain:30002
connected to inet:localhost.localdomain:30002
sent:"/var/tmp/gps_pty0
"
line="OK"
parameters: 4800 none 8 1 "\n" 1 0 prompted=false
$GPRMC,152515,A,4003.0021,N,10500.2309,W,000.0,240.5,010415,008.9,E*68\r\n
$GPGGA,152515,4003.0021,N,10500.2309,W,2,10,1.0,1690.0,M,-18.0,M,,*46\r\n
$GPRMC,152516,A,4003.0021,N,10500.2309,W,000.0,240.5,010415,008.9,E*6B\r\n
$GPGGA,152516,4003.0021,N,10500.2309,W,2,09,1.0,1690.0,M,-18.0,M,,*4D\r\n
$GPRMC,152517,A,4003.0021,N,10500.2309,W,000.0,240.5,010415,008.9,E*6A\r\n
$GPGGA,152517,4003.0021,N,10500.2309,W,2,08,1.9,1690.0,M,-18.0,M,,*44\r\n
But its NTP offset has been wandering around. I added 50m as an NTP server for it, and the GPS clock on 100m is disagreeing with 50m:
ntpq -p
remote refid st t when poll reach delay offset jitter
==============================================================================
*192.168.0.5 .GPS. 1 u 45 64 377 0.946 118.340 33.872
LOCAL(0) .LOCL. 10 l 64 64 3 0.000 0.000 0.031
oGPS_NMEA(0) .GPS. 0 l 15 16 377 0.000 -849.69 347.187
On flux, chronyc shows that the clock for 100m is off from the others:
chronyc sources 210 Number of sources = 6 MS Name/IP address Stratum Poll Reach LastRx Last sample =============================================================================== ^* 50m 1 10 377 321 -125ns[ +15us] +/- 733us ^- 100m 1 6 77 35 +90ms[ +90ms] +/- 1570ms ^+ 150m 1 10 377 535 +6715ns[ +20us] +/- 619us ^+ 200m 1 10 377 476 -4792ns[+9000ns] +/- 831us ^+ 250m 1 10 377 497 +4392ns[ +18us] +/- 857us ^+ 300m 1 10 377 252 +2000ns[+2000ns] +/- 656us
Comparing the output of "data_dump i 2,10 A" on 100m with that from 50m shows intermittent data gaps of 1.269 seconds, whereas with 50m the two GPS records ($GPRMC, and $GPGGA) are reporting at 1 Hz, with quite consistent delta-Ts close to 0.85 and 0.15.
I updated /etc/ntp.conf, and changed the time2 parameter from 0.8 to 1.2 seconds:
# time2 time
# Specifies the serial end of line time offset calibration factor,
# in seconds and fraction, with default 0.0.
Now the GPS is agreeing with 50m:
ntpq -p
remote refid st t when poll reach delay offset jitter
==============================================================================
+192.168.0.5 .GPS. 1 u 61 64 377 0.941 -0.204 0.056
LOCAL(0) .LOCL. 10 l 42m 64 0 0.000 0.000 0.000
oGPS_NMEA(0) .GPS. 0 l 4 16 377 0.000 -0.118 0.031
So it appears that the serial data from the 100m GPS (which provides the time label for the precise pulse-per-second) was late from time to time, resulting in NTP having to struggle to figure out what time it is. So, for data up to today, I would not rely on the 100m data to have time-tags with any accuracy below 1 second. D'oh...