
With a break in the rain, and mid-level tide, we took a quick run into the marsh today:
S6: shot boom angles (but the CSAT angles were not correct)
S7: shot boom angles (same issue with CSAT)
S15: shot boom angles (same issue)
collected soil core (horrendous! corer was rusted, roots tenacious, gnats all over)
checked out S1's old Qsoil wisard board and probe. Definitively isolated problem to EC-5 probe. Red wisard board is okay.
S8: shot boom angles (same issue)
Made it out under the bridge with 4cm to spare.
Around 4pm yesterday, data stopped being processed in Boulder. There are no UDP or netcdf files for last night and webplots of course weren't created. (UDP data were saved here by eddy and presumably all data are on the stations.) I found that, although dsm_server was running, data_stats, for example, wasn't showing anything.
Thus, I killed dsm_server on barolo and let crontab restart it. Now UDP files are being created, but I still didn't see netcdf files. So, I killed statsproc as well and the next 15min crontab cycle restarted it. We're now creating netcdf files again.
It still is a puzzle to me how dsm_server could hang in a state of not relaying data...
9/26/16
Summary: Intermittent heavy rain last night and this morning. Tower DSM needed a reboot and station 12's usb memory has apparently failed but has been replaced using internal memory in the config file.
Actions past 24 hours:
- Yesterday (9/25) Station 3 needed the cell modem reset in the morning.
To dos:
- Reshoot all boom angles (just because...Have done 6 sites so far)
- Soil core samples (need S15, could redo S9, S1 waiting for Qsoil fix)
- Time for another rad cleaning (but probably will wait until rain stops later in the week)
- Install TP01 when fixed
- Fix WWW plots that die too frequently
Sensor Status:
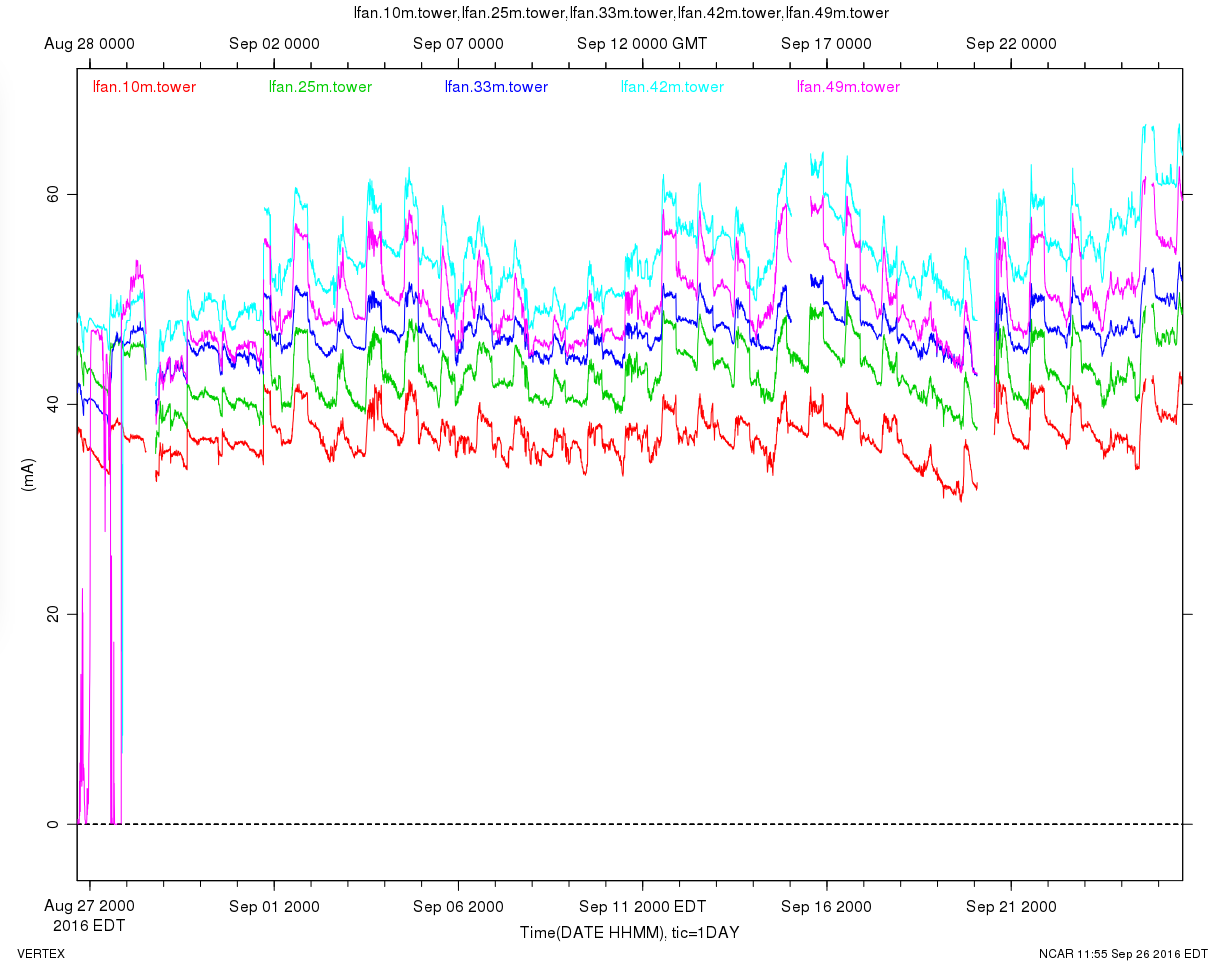
T/RH: ok, Ifan.42m getting large (and shutdown sensor last night). Not much we can do.
P: ok; Pirga still lower by about 1mb
2D Gill: ok
csat u,v: ok
csat ldiag: ok
csat w, tc: ok
EC150: ok
motes: ok
Wetness: ok
radiation: ok
Tsoil: ok
Gsoil: ok
Qsoil: S9 and S15 ok; S1 is dead (next step is to test it at S9 or S15)
Cvsoil: still need to have John/Steve S come up with a fix (in Boulder)
Rainr: ok
Vbatt: ok
Noticed that TRH.42m Ifan was at 0, indicating that it finally went over 80mA last night. However, when I tried to connect (either rs or minicom), it didn't respond, nor to eio cycles. Tried rebooting the box and it never came up. Walked to the DSM and had no response on the console. Finally power cycled the DSM and everything came back up, including TRH.42m with Ifan now 63mA.
As mentioned before, we'll keep watching this sensor.
It was annoying to have tower DSM flake out like this, though.

The USB disk on S12 died over the weekend. The rsyncs of s12 from barolo started to fail, and then upon logging into s12 found that the sda disk no longer showed up in lsusb. So it looks like the disk has just died. I have changed vertex.xml to comment out the <mount> element, and instead created a link from /media/usbdisk/projects to /home/daq/data/projects, so now the raw archive files are being written to the home partition:
daq@s12:~/isfs/projects/VERTEX/ISFS/config$ lsu
Filesystem Size Used Avail Use% Mounted on
/dev/mmcblk0p2 856M 2.4M 793M 1% /home
total 780
-r--r--r-- 1 daq eol 795677 Sep 26 23:01 s12_20160926_225143.dat
With almost 800M available and writing 54M per 12 hours, that means there is room for 7 days of data. If I change the rsync configuration to remove more data and only leave the most recent 2 days of data at the site, then S12 could be offline for almost 5 days before it starts losing data. So maybe you'd prefer to go without a new USB disk, it certainly seems feasible.
If you choose to replace it with another 8GB disk, then once you insert it, it can be formatted remotely on the DSM, and then the configuration needs to be switched back to using the mount option.
We have noticed that the tower Ifan values are getting rather large (more than 60mA). Here is the plot over the past month, where especially 42 and 49m (of course ![]() ) are at times running significantly higher than the others. The only <possible> action that we could take would be to turn them off to conserve potential run time on the fans. However, stopping the fans might allow stuff to build up more and humidity to do more damage (since the fans wouldn't be warm). Furthermore, the sonic temperatures appear to be <reasonably> close to the TRHs, so if a sensor dies, a tower temperature profile could still be constructed.
) are at times running significantly higher than the others. The only <possible> action that we could take would be to turn them off to conserve potential run time on the fans. However, stopping the fans might allow stuff to build up more and humidity to do more damage (since the fans wouldn't be warm). Furthermore, the sonic temperatures appear to be <reasonably> close to the TRHs, so if a sensor dies, a tower temperature profile could still be constructed.
Thus, we won't take any action here and hope the TRHs last. At the rate they are going, they should still be under 80mA for another month. (If not, the current threshold could be raised.)
S3 was still down this morning, so it was a good excuse to take the new boat out for a spin. ifdown eth1/ifup eth1 got the network back up and all was well. As usual, data were saved locally, so no data were lost.
Despite the fun, this is getting old, so I've now installed (updated and put into crontab) the net_check script on every system in the marsh. Previously, it had only been running on S8. As another test, I did this all on eddy which is now running VPN (thanks, Gordon).
9/26/16
Summary: Light winds and clear skies again today. Station 3 was not reporting this morning. A short trip to the field has it back online.
Actions past 24 hours:
- Yesterday (9/25) Quiet day in the command post.
To dos:
- Reshoot boom angles (just because...)
Sensor Status:
T/RH: ok
P: ok; Pirga still lower by about 1mb
2D Gill: ok
csat u,v: ok
csat ldiag: ok
csat w, tc: ok
EC150: ok
motes: ok
Wetness: ok
radiation: ok
Tsoil: ok
Gsoil: ok
Qsoil: offline
Cvsoil: still need to have John/Steve S come up with a fix (in Boulder)
Rainr: ok
Vbatt: ok
I've been away this afternoon, and the netcdf files were down, so I don't know how long this connection has been down. Hopefully, it will come up later. If not, it will be a perfect use for my new boat!
Netcdf files hadn't been updated at EOL since this morning.
data_stats sock:barolo showed no data.
nidas_udp_relay was running on eol-rt-data, though it had been restarted this morning at 09:50 MDT. It wasn't due to a reboot, it's been up for 50 days.
On eol-rt-data, "data_stats sock::30010" showed data coming in. Or you can do, from any system at EOL:
data_stats sock:eol-rt-data.fl-ext.ucar.edu:30010
These errors started showing up in /var/log/isfs/isfs.log, every 10 seconds:
Sep 25 09:41:10 barolo dsm_server[44405]: ERROR|SocketConnectionThread: IOException: inet:128.117.188.122:30010: connect: Connection refused
Eventually the socket open succeeded, but then this error:
Sep 25 09:50:11 barolo dsm_server[44405]: WARNING|SampleInputStream: inet:128.117.188.122:30010: raw sample not of type char(0): #bad=1,filepos=0,id=(609,25461),type=28,len=779247971
As with reading disk data, the reader skips forward one byte and looks for a good sample.
Not sure why the corrupt data, and why it didn't recover. Would be good to look at the logs on eol-rt-data.
Did a kill -TERM of dsm_server on barolo, and ran check_vertex_procs.sh by hand, rather than waiting for crontab.
Updated crontab to check the procs every 15 minutes, rather than 30.
Date Time | Position | Tare (g) | Wet (g) | Dry (g) | rho (g/cm^3) | Moist (%) | Moist (%) | Comments |
|---|---|---|---|---|---|---|---|---|
9/24 09:38 | S9 3-6cm | 8.2+73.3 | 159.2 | 99.2 | 0.27 | 90.3 | 67.4 | Had to undercut sample to break it out of root mat |
| 9/27 15:50 | S15 3-6cm | 8.2+73.3 | 162.9 | 103.9 | 0.34 | 88.8 | 64.7 | Undercut; tenacious roots; rusted corer; core slid w.r.t. rings |
| 10/11 14:30 | S1 3-6cm | 8.2+73.3 | 165.1 | 99.7 | 0.27 | 98.4 | 62.4 | Tenacious roots |
tare = c(8.2+73.3,8.2+73.3,8.2+73.3)
wet = c(159.2,162.9,165.1)-tare
dry = c(99.2,103.9,99.7)-tare
vol = c(3)*pi*(5.31/2)^2
moist = 100*(wet-dry)/vol
rho = dry/vol
m = moist
grav.moist = m
grav.comp = m
ec5 = c(67.4)
matplot(grav.comp,ec5,xlim=c(0,60),ylim=c(0,60)); abline(0,1,lty=2); abline(-8,1,col=3,lty=2)
9/25/16
Summary: Calm and clear skies today. All stations working normally this morning.
Actions past 24 hours:
- Yesterday (9/24) Reset tower 12 cell modem, took a soil sample and retrieved the S1 QSoil sensor which isn't reading.
To dos:
- Reshoot boom angles (just because...)
Sensor Status:
T/RH: ok
P: ok; Pirga still lower by about 1mb
2D Gill: ok
csat u,v: ok
csat ldiag: ok
csat w, tc: ok
EC150: ok
motes: ok
Wetness: ok
radiation: ok
Tsoil: ok
Gsoil: ok
Qsoil: offline
Cvsoil: still need to have John/Steve S come up with a fix (in Boulder)
Rainr: ok
Vbatt: ok
Tonight, noticed long periods of wind outages at S8. The rserial output show that these period have data values of 999.99 with an error code=04 (the manual says that the value of this code provides "no useful information to the user"!). However, I also see reasonable data interspersed with the bad periods. I suspect a bird is roosting in the array (despite Dan's heroic effort at making bird spikes) and that this problem will go away. Just to do something, I ddn/dup and eio 6 0/1, to no effect.
We've noticed that tower's battery capacity is marginal to bridge the cloudy days that we've had recently. Thus, we decided simply to add a battery to tower. This was just done a few minutes ago. We managed to keep the first battery connected through this change, so the station and power mote configuration stayed up.
9/24/16
Summary: Light winds and cloudy skies today. Station 12 was not reporting in this morning. A field trip found the cell modem was not working. Reset the tower and left when it all appeared to be working. Recovered the QSoil sensor from Station 1 and took a soil sample from Station 9 while getting some boom angles from 1, 9, 10, and 12 to round out this trip.
Actions past 24 hours:
- Yesterday (9/23) investigated TRH and decided the fan current sensor board was faulty. Found corrosion on several pins in connectors and one wire had corroded and broken off under the heat shrink covering a splice. Repaired the wire, replaced the board, tested and found the unit runs slowly but shows 329mA of current which is not right either so it will have more time spent on it soon.
To dos:
- Reshoot boom angles (just because...)
- troubleshoot mote from S9
Sensor Status:
T/RH: ok
P: ok; Pirga still lower by about 1mb
2D Gill: ok
csat u,v: ok
csat ldiag: ok
csat w, tc: ok
EC150: ok
motes: ok
Wetness: ok
radiation: ok
Tsoil: ok
Gsoil: ok
Qsoil: offline
Cvsoil: still need to have John/Steve S come up with a fix (in Boulder)
Rainr: ok
Vbatt: ok