
Sonics and gas analyzers
rsw02 20m
Replaced around 16z with help from Orson (ND).
v07 4m
Since this is a RMYoung, the problem could be related to voltage, but we have no more 14V adapters. The easiest replacements are the last working RMYoung, which reports about 2% bad samples in the ops center, and a Metek, since the Meteks mount onto the Samortechnica booms.
We visited the site around 17z, and measured 12.45V at the port 2 bulgin pin, and 12.85V at the power panel input pin. So I'd guess the RMYoung is getting enough volts since it is only 4m up. Vdsm is always more than 12V, even though it is measured at a soil mote 5m from the DSM.
I forgot to bring a ladder to look at the adapter in the junction box, so at the moment I'm assuming it's a 14V and it's performing well enough that the voltage should be high enough for the RMYoung.
tnw09 10m
Diagnostic flipping back and forth.
tnw07b 4m
Diagnostic mostly bad.
tse10 10m
Some spiking.
TRH Sensors
tse04 60m
INEGI replaced it, working now.
tse11 60m
Still needs to be replaced.
Sonics and gas analyzers
tse07 10m sonic
Replaced and working.
rsw02 20m
Still down, still needs to be replaced.
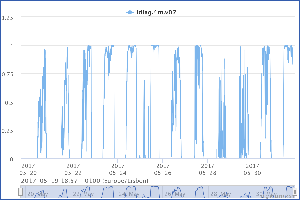
v07 4m
Still suspicious. A plot of ldiag.4m.v07 over the last several days is below, and the bad periods look diurnal. Maybe a temperature problem? This is an RMYoung, so I can look for a working RMYoung spare with which to replace it.
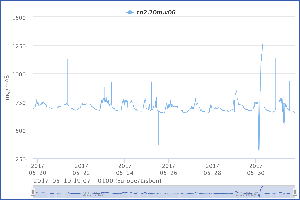
v06 20m LiCOR
Still missing samples later in the day, but it doesn't look that bad judging from a plot of the last several days. I think lidiag is usually non-zero, so the only diagnostic that matters is how many of co2.20m.v06 and h2o.20m.v06 are missing. It does look like it's getting worse, but I don't know of anything we can do about it since we have no spares.
TRH Sensors
tse04 and tse11 60m
INEGI will replace at least tse04 tomorrow.
Other issues
tnw08 Vdsm
Still not there. Steve says we have no more voltage motes, so it will never be there.
LiCORs for rsw01 and rsw07
The ARL shipment did not arrive today. Chris says ARL is going to plan as if they won't arrive and make do with the instruments they have.
Sonics and gas analyzers
tse07 10m sonic
Still down, we will replace the 10m CSAT3 at tse07 with help from Orson from ND.
rsw02 20m
RMYoung on port 3 is still not reporting, even after more power cycles. We will plan to replace it.
v07 4m
According to ldiag.4m.v07 in qctables, RMYoung sonic was flagging up to 80% of samples as bad later in the day. However, spd.4m.v07 and w.4m.v07 have no missing values in that time period. How is that happening?
v06 20m LiCOR
Many missing samples later in the day.
tse12 10m
ldiag is occasionally non-zero, like less than 0.1%, so nothing that needs to be fixed.
TRH Sensors
tse11 2m
Replaced.
tse04 and tse11
60m TRH sensors on tse04 and tse11 are still down, planning for INEGI to replace them.
Other issues
More inventory checking. Updates are on the spreadsheet linked from Spares Inventory page.
Cycled power on rsw02 to recover from a presumed OS hang up. It's a known problem that has not happened in a few weeks.
Isabel inventoried soil sensors, so we filled in those and some other details on the inventory spares, and the spreadsheet was moved to google drive.
Prepared TRH and CSAT3 replacements, tested on a DSM setup in the ops center.
I think the trick was to open pavucontrol, find the GF108 HD Audio output, and then unmute it by clicking the mute toggle button. I also muted the built-in audio analog output.
In System Settings -> Multimedia -> A&V, Audio Hardware Setup tab, select GF108 and the profile (HDMI 4).
In the Device Preference tab, I also played around with moving the GF108 up in the preference priority for the Video and Communication categories, but after some more experimentation I'm not sure that made any difference.
Google Chrome sometimes cannot open the USB video camera. It seems to help to just keep selecting the video device in the camera dropdown in the Hangout Settings dialog. Eventually Chrome opens it. Maybe restarting Chrome or unplugging the USB video camera and plugging it back in would help also.
In the Hangout Settings dialog, make sure the audio output is set to the Default, not to the built-in audio output or to the HDMI output.
Today I reviewed cockpit and learned that sensors which have not reported for a while get dropped from qctables, so now we have an expanded list of problem sensors. Isabel went through all of them and diagnosed whether they were reporting or not, and cycled power on each of them, which fixed just one: the LICOR on v04.
Sonics and gas analyzers
tse07 10m recovery short-lived
After coming back for several hours yesterday, this sonic has been logging only bad samples. It looks like the best option is to replace it.
rsw02x 20m
RMYoung on port 3 is not reporting. Also dropped from QC table. It's last sample was May 24 22:50 UTC.
rsw07 20m LICOR
Per Steve's comment below, this and the rsw01 missing data are because these are the ARL LICORs which have not been installed yet.
rsw01 20m LICOR
LiCOR on port 5, power cycled, still no data. There have been no samples from it for all of May, and none when it started recording in March. As it turned out, this is one of the LiCORs yet to be installed.
v04 10m LiCOR
It was down for a while. Isabel cycled power on it, working now.
TRH
tse04 60m
The 60m.tse04 TRH was dropped from QC table, so at first I thought it had recovered. It is still not responding, so it needs to be replaced.
tse11 2m
Cycled power, still no data, replace.
tse11 60m
Cycled power, still no data, will have to ask INEGI to replace it.
Power problems
No changes. tse05 still going down in the early morning, just need to visit and adjust the solar panel.
Motes
tse02 Vheat and lambdasoil
Vheat missing from 5/29 11:45 to 14:47. It looks like it exceeded the max limit of 1.3 for it's 3-hourly sample updated at 11:45. Is anything about 1.3 really invalid? Or does the max in the configuration need to be increased for Vheat?
tnw08 Vdsm
Voltage mote is dead, not responding even after a power cycle. We can replace it.
Other issues
I modified the perdigao.cdl so it contains all the variables expected in the 5-minute statistics output, in the hopes qctables would show missing values for sensors which are no longer reporting. However, that doesn't quite work yet, and I just realized it will interfere with the high-rate CDL, so more work is needed on that idea...
I configured the eddy audio output for HDMI for the teleconference today, details in another blog.
The Confluence wiki was down this morning so blog entries got put off for a while.
Sonics
tse07 10m recovery (sort of)
tse07 10m sonic started working again probably from around 04:00 to 12:00 UTC, and then it went out again.
That sonic is a CSAT3, for which we have two spares. So we could go the route of replacing the whole sensor, but that includes the electronics box as well as the head.
TRH
No changes.
Power problems
No changes.
Other issues
Robert tells me that he is hooking up fine-wire temperature sensors on the ARL towers. At the moment they are installed at every level on tnw16, and (eventually if not already) will be on most levels except the highest on the other towers. The sensors are connected to channel A1, so they are being recorded at 20Hz in the existing data stream. Once I get the coefficients from Sean and a list of which heights have a sensor connected, we can configure NIDAS to process that channel into a high-rate temperature variable.
The high-rate netcdf broke when the variables changed, so that's been fixed, and those files are now copied to ftp for public download.
The Tcase.in.v04 is a KZ radiometer, so maybe that does have individual connections that I can check. If it doesn't, then what should I do? Do we have a spare KZ somewhere? Or could I replace the whole KZ with a NR01 (or install a NR01 as an addition to the KZ)?
Sonics
tse07 10m still reporting nans
I suppose we will visit the site and see if there's an obvious obstruction, otherwise we will look for a spare and arrange to replace it.
TRH
tse04 60m TRH still down
I will prepare to replace it with one of the spares and let us Jose Carlos know we need some climbing help.
Power problems
Solar charging at tse05
Isabel and I went searching for tse05 and finally found it. Steve recommends bringing up some longer power cables and re-orienting the single solar panel, but this site is not considered a high priority. We could also bring up a second solar panel, but we'll save that as the last resort. It has also been overcast the last few days, so with a string of sunny days and the panel more horizontal the site may get enough charging.
Other issues
v04 Tcase.in
v04 Tcase.in was out from 12-18 (WEST), came back, was out for most of 2017-05-28,00:00-06:00, and now is back again. Maybe a loose connection? Moisture?
eddy lock-up
eddy froze during the daily briefing teleconference, including getting stuck in an audio loop, and it needed to be powered down by holding the power button. So far I've just done an update.
Follow-up on 2017-05-28: I helped Chris get the video going in google hangout on eddy. We had to go to hangout settings and select the video device in the dropdown menu (there is only one option). After selecting it a couple times, the video finally started working.
I have not worked on getting the HDMI audio output working.
Power problems
tse05
Site goes down for a few hours every night, and voltage plots show it is the batter dying. Maybe it needs a reposition of the solar panels or another battery?
Sonic problems
tse07 10m
CSAT3 on port 1: reporting but all samples flagged as bad, even after a power cycle.
tnw11 20m
RMYoung on port 4 was stuck repeating the same message:
0.00 0.00 0.00 -30.65 2
0.00 0.00 0.00 -30.65 2
0.00 0.00 0.00 -30.65 2A power cycle fixed it.
rne07 20m
This is a CSAT3A IRGA. The winds and IRGA were bad most of the day, but it cleared up eventually.
4m.v07 and 4m.tnw07
As many as 80% bad samples, but in the last 6 hours of the day was trending down to 13%. Similar for tnw07 4m, 72% bad in the 3rd quarter down to 6%. Presumably there's nothing to be done about them but make sure they keep trending to fewer bad samples.
v06 20m
I was suspicious of h2o from the Licor on port 5 because of the number of NAs, but I've decided it looks fine compared to the others.
TRH problems
tse06 2m TRH
INEGI climbers replaced 1A fuse on port 0 and now TRH is working.
tse04 60m TRH
TRH on tse04t port 1 is out, power cycle does not help, so maybe it's a fuse or broken sensor.
tse04 100m TRH
TRH on tse04t port 3 was reporting messages with T=200 and RH=0:
TRH111 200.22 0.00 45 0 6138 1879 141\r\n
TRH111 200.22 0.00 44 0 6138 1879 138\r\n
TRH111 200.26 0.00 48 0 6139 1879 150\r\nA power cycle seems to have fixed it.
tse13 100m TRH
TRH on tse13t port 3 was having the same problem as 100m TRH on tse04:
TRH56 199.07 0.00 30 0 6143 1862 95\r\n
TRH56 199.07 0.00 31 0 6143 1862 99\r\n
TRH56 199.07 0.00 30 0 6143 1862 94\r\nPower cycle fixed it:
pio 3 0
pio 3 1
rs 3
...
TRH56 21.69 63.07 32 0 1535 116 101\r\n
TRH56 21.73 63.07 30 0 1536 116 94\r\n
TRH56 21.69 63.07 31 0 1535 116 99\r\nOther problems
v04 Tcase.in
It was missing for most of the day, but it has since recovered.
There are 2 types of box configurations used in the project. This post is intended to be a reference on their configurations.
The first breaker box has a terminal block and circuit breaker. It delivers 240 straight to the tower. A small indicator is directly above
the switch. Red means the output is live, green means the breaker is tripped. The lever will be down when tripped as well.

The other box only has a terminal block and a 12V power supply. The supply output is run through the long connector to the green cable and to the tower.

Some boxes share other phases with nearby equipment like Lidars so there may be extra breakers inside the box.

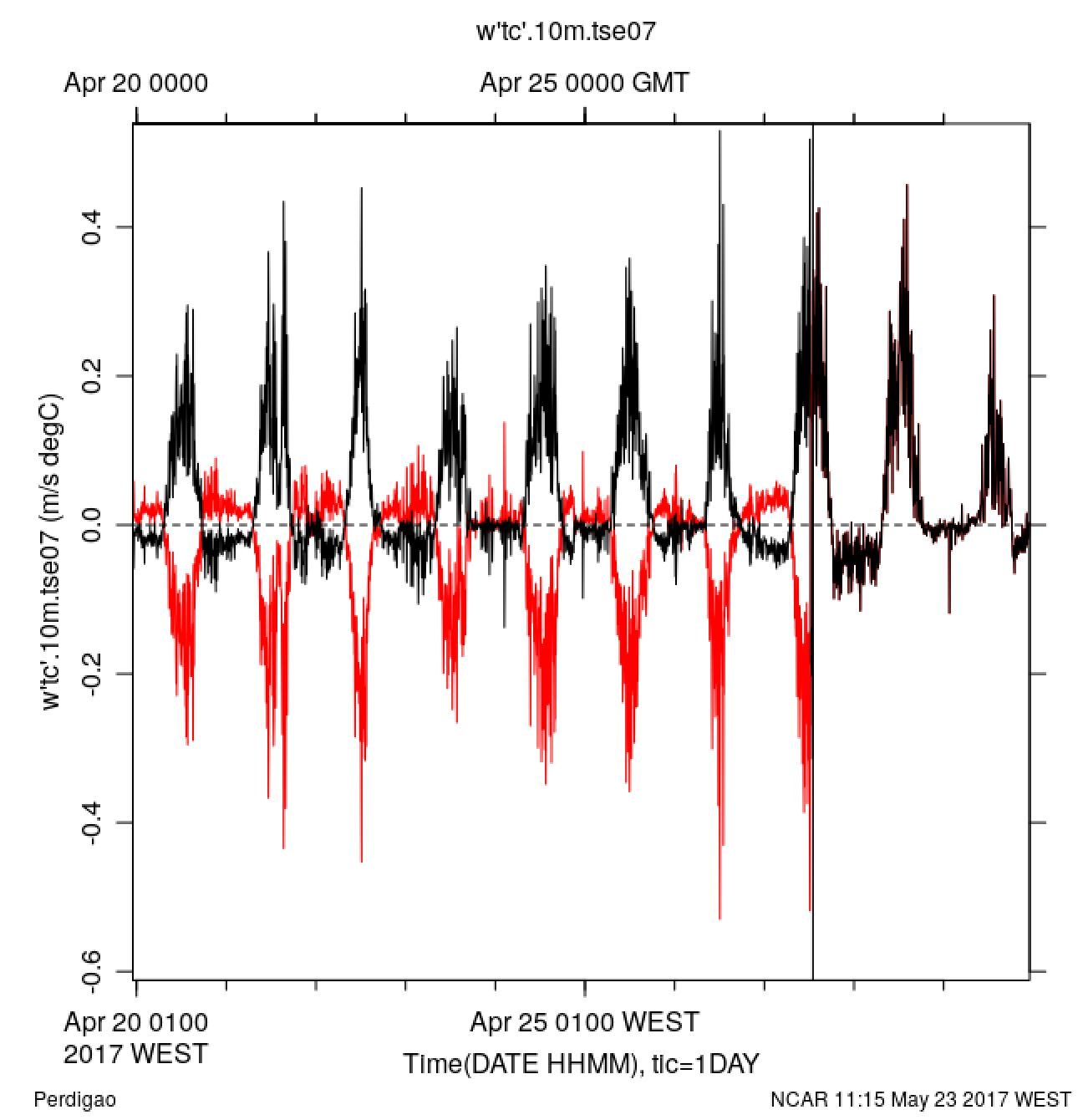
I don't see it in logbook, but the data make it obvious that 10m.tse07 was upside down until about 27 Apr 14:00. Multiplying the heat fluxes by -1 prior causes them to make sense.
Good catch, whoever noticed it!
After the meeting, Andy and I did a zip through the valley:
- tnw07: power cycled ubiquiti (by Bluetoothing into tnw07b, ssh to tnw07t, then pio dcdc 0/1. After a minute, this was back online.
- v07: soil core
- tnw06: flip the cooler
- tnw05: soil core; flip the cooler
- rne06: soil core
- rne07: soil core
- tnw09: flip the cooler
- v04: soil core
In an effort to mitigate the problem of water in the battery boxes it's been decided to flip the box, mount the batteries and controller on the lid, and then use the box as the cover.

Tying off or looping the cables at the top with the controller will ensure they will always be well above the waterline for any that gets into the box. At this time towers tse05 and tse07 have been flipped.

Securing the box with a few rocks will be standard, and fortunately there's a few around to choose from.
Today took cores at rsw04, v01, rne01, and tse12 as part of showing Matt and Luis Frohlen around.
I'm puzzled by the gravimetric soil sample table. Entries are made for v06 on 6 Apr and for rne03 on 14 Apr, and the v06 entry even says part of sensor installation. But there are no soil sensors at either of these 2 sites. Also, the samples for v01 and tnw05 don't have dry weights recorded – hopefully someone has these! Finally, I don't find an installation entry for tse01, which came online on 11 Apr. Perhaps saving/processing a core was forgotten in the effort to get the sonic working there.
After today, we should have a density sample for every soil site. However, there still are a lot that we don't have even one moisture comparison since the station was not operational at the time of the soil sensor install. I note that the few sites where we now have 2 samples are mostly in the same soil moisture conditions. We really need a set of cores in moist conditions. Perhaps the rain expected later this week will provide that (but not cause more instrument problems!)
tse05: NR01 died sometime yesterday. pio doesn't work. Will need another hike to the ladder.
tse06: 2m TRH still dead – suspect fuse blown. INEGI hopefully will climb to 30m when they are here on Tues.
rne06: LiCor died, pio restarted
v06: LiCor died, pio restarted (our crontab should have restarted within 4 hours anyway)
We just returned from adding both a ground rod and a wire jumper connecting the grounds from the DCDC converters, which <finally> made the RMY happy. Its data now appear reasonable.
This (almost) completes the tower installation. The last step is to install the 2 ARL Licors, expected to arrive Tues.