
Yesterday, I finally grounded both the guy wire and the DSM. However, I forgot that I had noticed the DSM being down and staying down the day before. Thus, the DSM stayed down all day. The Ubiquiti was up and connected, according to the LEDs. I also yesterday noticed an issue when I couldn't ping anything on our Marshall wifi network for an hour or so in the afternoon. This problem went away later on.
This morning, I found the console port on the Pi to be unresponsive, so I did a power reboot to the DSM. Everything seemed to come up okay, and we are getting ncharts data again.
As an additional precaution, I adjusted the Ubiquiti azimuth to point east of the station adaptor, to give it more beam separation from SPol. I still had the full (4?) LED signal strength indicator. With a ~30-degree half beam width for the NanoBeam, it still will see some SPol signal.
SPol ran briefly (one complete scan) while I was there and the DSM stayed up, but I don't know if SPol was transmitting. We'll keep monitoring...
Steve gave a soil sampling tutorial to Chris and Jacquie at Marshall in the afternoon ~3-4pm. We also wanted to test the gravimetric data form that is on the ISFS shared drive. Gary met us out there for DSM troubleshooting (see previous post).
It was so windy we could not get accurate weight readings so we did the tare and wet weights in Steve’s van. Chris took photos - maybe he’ll add them to this post.
We quickly realized there are a few things in the form that are missing or needed adapting. I plan to modify the form for the next soil sample.
FYI - to fill in the Gravimetric form you have to ‘send’ yourself the form or choose the 'Get pre-filled link' option otherwise you are in edit mode. It would be good to know if there is a way to fill this form offline.
Measurements made 20 August 2021 after 3:23pm
Qsoil ~ 0.058 %Vol
Tin number 1 = 21.0 g (with lid on)
Wet weight = 88.7 g
PS: Reminder to fill up the tupperware of grease.

On Friday afternoon, 2021-08-20, Steve, Chris, Jacquie, and I were at Marshall. The DSM and Ubiquiti were again rebooting intermittently. Jiggling connectors inside the battery box did nothing. Steve saw a little corrosion on the cable connection at the victron which supplied power to the DSM. Chris pointed out that the power cables have two conductor pairs for 12V, so it seemed extremely unlikely the problem could be a poor connection in the power cable. Steve replaced the Victron, but the power interruptions continued after that.
We looked for a pattern in the timing of the reboots:
egrep -a -C 3 "Booting Linux" messages > booting-linux-messages.txt
The file is attached: booting-linux-messages.txt. (This would be a great situation in which to have a battery-backed system clock on this DSM.)
Nagios shows ttstation down during 16:00 hour at these times:
Host Down[08-20-2021 16:57:45] HOST ALERT: ttstation;DOWN;HARD;1;CRITICAL - 128.117.81.51: rta nan, lost 100% Host Down[08-20-2021 16:53:46] HOST ALERT: ttstation;DOWN;HARD;1;CRITICAL - 128.117.81.51: rta nan, lost 100% Host Down[08-20-2021 16:49:47] HOST ALERT: ttstation;DOWN;HARD;1;CRITICAL - 128.117.81.51: rta nan, lost 100% Host Down[08-20-2021 16:45:43] HOST ALERT: ttstation;DOWN;HARD;1;CRITICAL - 128.117.81.51: rta nan, lost 100% Host Down[08-20-2021 16:37:43] HOST ALERT: ttstation;DOWN;HARD;1;CRITICAL - 128.117.81.51: rta nan, lost 100% Host Down[08-20-2021 16:33:39] HOST ALERT: ttstation;DOWN;HARD;1;CRITICAL - 128.117.81.51: rta nan, lost 100% Host Down[08-20-2021 16:26:39] HOST ALERT: ttstation;DOWN;HARD;1;CRITICAL - 128.117.81.51: rta nan, lost 100% Host Down[08-20-2021 16:21:40] HOST ALERT: ttstation;DOWN;HARD;1;CRITICAL - 128.117.81.51: rta nan, lost 100% Host Down[08-20-2021 16:13:48] HOST ALERT: ttstation;DOWN;HARD;1;CRITICAL - 128.117.81.51: rta nan, lost 100% Host Down[08-20-2021 16:06:40] HOST ALERT: ttstation;DOWN;HARD;1;CRITICAL - 128.117.81.51: rta nan, lost 100%
The reboots file looks like reboots happened during that same hour at these times:
22:52 22:47 22:41 22:39 a few reboots in between which never got time sync 22:23
No clear pattern. It's even difficult to see if the nagios ttstation failures line up with the reboots. Past incidences did seem to be at regulat 10-12 minute intervals, but not this time.
The SPOL conjecture
Steve and Chris measured the batteries, looked for problems on the power interface card, and we scratched our heads for a while, then came the real kicker. Steve realized that SPOL had been running while the reboots were happening, and now that SPOL had stopped, the DSM had not rebooted. Since we could find no indication of a problem in the hardware, the current running theory is that SPOL radiation was somehow interrupting power. That also happens to explain unexpected outages in the iss4station Ubiquiti radio. Nothing else at that site has gone down, except for the ubiquiti, with its antenna pointed almost directly at SPOL.
Steve has emailed RSF to find out when SPOL has been running recently, so we can see if that coincides with the problem periods.
In the meanwhile, the DSM was turned around on the pole, so the metal backplate is facing SPOL and can provide some shielding. Steve also grounded the DSM, as a matter of good practice.
No DSM reboots in the following 24 hours, and no iss4station outages, but probably SPOL has not been running.
Mitigation?
If the problem does turn out to be SPOL, and assuming the DSM can be shielded, I'm not sure how we can mitigate the interference with the Ubiquiti radios. The other radios have not had problems, so apparently it's enough to point the radios away from SPOL. However, that would mean introducing another radio which can point at pedestal without pointing towards SPOL, then pointing iss4station and ttstation at that intermediate radio.
The DSM had been rebooting intermittently, so I visited the site around 4:30 pm 8/19 MT.
While there wondering if there was a way to unlock and open the battery box, I heard the TRH fan drop off and then start up again immediately. So the power outage was brief. I also noticed the ttstation ubiquiti wifi was up, which only happens for the first 15 minutes after boot. I connected to the ubiquiti and confirmed uptime of 10 minutes.
Wiggling the plug in the gfi outlet in the weatherproof box did nothing.
I verified poe passthrough is off on the radio, so I am able to connect to the DSM through the radio lan2 port. Just to remove the switch as a possible failure point, I disconnected the power from the switch and connected the ubiquiti directly to the Pi.
I had to restart the json data service after the system date updates, and then dashboard looked good.
systemctl --user restart json_data_stats
The power outages could be caused by a problem in the victron, so I looked for messages from the victron in the raw data which might indicate an error
aq@tt:~ $ lsu USB1: Filesystem Size Used Avail Use% Mounted on /dev/sda1 58G 1.8G 53G 4% /media/usbdisk -r--r--r-- 1 daq eol 117670 Aug 19 19:25 tt_20100201_000129.dat -r--r--r-- 1 daq eol 189288 Aug 19 19:40 tt_20100201_000130.dat -r--r--r-- 1 daq eol 124325 Aug 19 19:52 tt_20100201_000131.dat -r--r--r-- 1 daq eol 119383 Aug 19 20:04 tt_20100201_000132.dat -r--r--r-- 1 daq eol 118837 Feb 1 2010 tt_20100201_000133.dat -r--r--r-- 1 daq eol 121911 Feb 1 2010 tt_20100201_000134.dat -r--r--r-- 1 daq eol 119202 Aug 19 22:28 tt_20100201_000135.dat -r--r--r-- 1 daq eol 116753 Aug 19 22:40 tt_20100201_000136.dat -r--r--r-- 1 daq eol 49322 Jun 24 23:01 tt_20100201_000851.dat -r--r--r-- 1 daq eol 8806338 Aug 19 23:04 tt_20210819_224007.dat
In chrony/tracking.log, the reboot after 22:38 utc (16:38 mt) took 1 minute 12 seconds to sync to PPS. I think that means the ublox is keeping leap seconds, and I'd bet pps starts sooner than that, so maybe we need to change some chrony settings to sync to it faster. Or maybe that's how long it takes chrony to start up, in which case a battery-backed system clock really makes sense.
2021-08-19 22:38:32 PPS 1 6.860 0.009 1.660e-07 N 1 5.438e-08 -2.242e-08 0.000e+00 9.651e-06 2.594e-05 =================================================================================================================================== Date (UTC) Time IP Address St Freq ppm Skew ppm Offset L Co Offset sd Rem. corr. Root delay Root disp. Max. error =================================================================================================================================== 2010-02-01 00:00:08 0.0.0.0 0 7.225 0.008 0.000e+00 ? 0 0.000e+00 -2.891e-16 1.000e+00 1.000e+00 1.500e+00 2010-02-01 00:01:12 PPS 1 7.225 0.008 -3.644e+08 N 1 1.209e-06 -2.989e-10 0.000e+00 4.525e+02 1.500e+00 2021-08-19 22:40:23 PPS 1 7.225 0.010 -9.001e-07 N 1 1.396e-06 -7.381e-11 0.000e+00 9.621e-06 3.644e+08 2021-08-19 22:40:39 PPS 1 7.224 0.017 -9.389e-07 N 1 1.322e-06 5.131e-07 0.000e+00 1.112e-05 2.937e-05 2021-08-19 22:40:55 PPS 1 7.223 0.030 5.480e-07 N 1 1.656e-06 3.884e-07 0.000e+00 1.168e-05 3.100e-05
There are no non-zero ERR reports in the latest data file:
data_dump -i 1,60 /media/usbdisk/projects/LOTOS2021/raw_data/tt_20210819_224007.dat |& egrep ERR | egrep -v 'ERR\\t0\\r' | less
I looked for a way to get an uptime from the victron, to see if the victron itself was power cycling, but I could not find that.
Looking at the wiki page for the victron (https://wiki.ucar.edu/pages/viewpage.action?pageId=398004758![]() ), the victron lowers the charging power by 50% every 10 minutes. Could that correlate with the outages?
), the victron lowers the charging power by 50% every 10 minutes. Could that correlate with the outages?
daq@tt:~ $ data_dump -i -1,60 /media/usbdisk/projects/LOTOS2021/raw_data/tt_20210819_224007.dat | grep PPV | cut -c 50-70 | sed -e 's/\\t/ /g' -e 's/\\r\\n//' -e 's/PPV//' | sort -n | uniq 2021-08-19,23:30:28|INFO|opening: /media/usbdisk/projects/LOTOS2021/raw_data/tt_20210819_224007.dat 2021-08-19,23:30:28|NOTICE|parsing: /home/daq//isfs/projects/LOTOS2021/ISFS/config/lotos2021.xml Exception: EOFException: /media/usbdisk/projects/LOTOS2021/raw_data/tt_20210819_224007.dat: open: EOF 21 21 22 23 24 24 25 25 26 26 27 27 28
The PPV is always from 21-28 V, so no sign that it is dropping off. However, if it dropped off suddenly, then that would kill everything before it could be logged.
I installed victronconnect app on my phone, got the bluetooth app and connection working, but I couldn't see any settings which could be causing output to cut. There is a setting to cut output according to battery temperature, but that is disabled. The output mode is "always on".
This afternoon I went to Marshall to swap out the existing tower dsm for a replacement I had set up over the last week. The existing dsm has been going off the net intermittently for the past 10 or so days (see previous posts). It had been on the net the entire time since I rebooted it on Tuesday, but when I checked just before leaving Foothills (~4pm) it was down. So, more reliable than it was earlier, but still not great.
The replacement DSM had new everything except the ethernet and USB patch cables and the POE injector. After powering it up I noticed it had no power to the serial board, then remembered we had to put a 3A fuse for it to work, so used the one from the other DSM, which fixed the power issue. I also noticed there was no power to the ubiquiti, which turned out to be fixable by wiggling all the connections for the POE injector (sorry Steve). I also unplugged the ribbon cable from the serial board to the power board, like in the existing DSM, so pio can't turn off power to the ubiquiti and the switch.
After making sure everything was powered I logged in, first with the console cable and then through the ethernet switch, to check data and networking, and found that the DSM was randomly rebooting or hanging. In the hour or so I spent trying to troubleshoot I don't think it successfully stayed up for more than 5 or so minutes between reboots. I also noticed that sometimes the dsm process wasn't running despite the DSM recently being rebooted, which sounds like the same problem I noticed in the old DSM last week that started this whole mess. It seemed that the DSM would work normally upon reboot at first, then after a few minutes would get much slower (commands like ifconfig and lsusb taking much longer than usual), and eventually the console would stop responding entirely until I rebooted the DSM. Often the ethernet interface seemed to go down first and I'd lose the ssh connection, but could still access the console through the console cable, then it would get slower and slower and finally hang. Did a little looking through logs but haven't found anything of use. Got part of one kernel error message, but the rest was cut off and I couldn't scroll up in minicom to see it:
[ 259.784447] r7:00000001 r6:8147db18 r5:80fe6108 r4:bb8110f0 [ 259.793432] [<80184d70>] (generic_handle_irq) from [<80675fb8>] (bcm2836_arm_irqchip_handle_ipi+0xa8/0xc8) [ 259.809290] [<80675f10>] (bcm2836_arm_irqchip_handle_ipi) from [<80184db4>] (generic_handle_irq+0x44/0x54) [ 259.825292] r7:00000001 r6:00000000 r5:00000000 r4:80e90d10 [ 259.834362] [<80184d70>] (generic_handle_irq) from [<80185514>] (__handle_domain_irq+0x6c/0xc4) [ 259.849308] [<801854a8>] (__handle_domain_irq) from [<801012c8>] (bcm2836_arm_irqchip_handle_irq+0x60/0x64) [ 259.865649] r9:81564000 r8:00000001 r7:81565f64 r6:ffffffff r5:60000013 r4:801088c4 [ 259.879499] [<80101268>] (bcm2836_arm_irqchip_handle_irq) from [<80100abc>] (__irq_svc+0x5c/0x7c) [ 259.894869] Exception stack(0x81565f30 to 0x81565f78) [ 259.903313] 5f20: 00000000 0004aea8 b6b682c4 80118e40 [ 259.917758] 5f40: ffffe000 80f05058 80f050a0 00000008 00000001 81031700 80cfc46c 81565f8c [ 259.932221] 5f60: 81565f90 81565f80 801088c0 801088c4 60000013 ffffffff [ 259.942642] [<8010887c>] (arch_cpu_idle) from [<809fee60>] (default_idle_call+0x4c/0x118) [ 259.957068] [<809fee14>] (default_idle_call) from [<80156514>] (do_idle+0x118/0x168) [ 259.970946] [<801563fc>] (do_idle) from [<80156838>] (cpu_startup_entry+0x28/0x30) [ 259.984619] r10:00000000 r9:410fd034 r8:0000406a r7:81049390 r6:10c0387d r5:00000003 [ 259.998656] r4:00000092 r3:60000093 [ 260.005199] [<80156810>] (cpu_startup_entry) from [<8010eaec>] (secondary_start_kernel+0x164/0x170) [ 260.020696] [<8010e988>] (secondary_start_kernel) from [<001018ac>] (0x1018ac) [ 260.031885] r5:00000055 r4:0155806a [ 260.038433] CPU2: stopping [ 260.043826] CPU: 2 PID: 0 Comm: swapper/2 Tainted: G D C 5.10.52-v7+ #1441 [ 260.057830] Hardware name: BCM2835 [ 260.064012] Backtrace: [ 260.068935] [<809eff28>] (dump_backtrace) from [<809f02b8>] (show_stack+0x20/0x24) [ 260.082188] r7:ffffffff r6:00000000 r5:60000193 r4:80fe5e94 [ 260.091192] [<809f0298>] (show_stack) from [<809f44c8>] (dump_stack+0xcc/0xf8) [ 260.102210] [<809f43fc>] (dump_stack) from [<8010e488>] (do_handle_IPI+0x30c/0x340) [ 260.115558] r10:80cfc46c r9:81562000 r8:8147e000 r7:00000001 r6:35cc2000 r5:00000002 [ 260.129144] r4:81049380 r3:f00ffb56 [ 260.135469] [<8010e17c>] (do_handle_IPI) from [<8010e4e4>] (ipi_handler+0x28/0x30) [ 260.148636] r9:81562000 r8:8147e000 r7:00000001 r6:35cc2000 r5:00000015 r4:814c13c0 [ 260.162013] [<8010e4bc>] (ipi_handler) from [<8018bd70>] (handle_percpu_devid_fasteoi_ipi+0x80/0x154) [ 260.177267] [<8018bcf0>] (handle_percpu_devid_fasteoi_ipi) from [<80184db4>] (generic_handle_irq+0x44/0x54) [ 260.193277] r7:00000001 r6:8147db18 r5:80fe6108 r4:bb8110e0 [ 260.202272] [<80184d70>] (generic_handle_irq) from [<80675fb8>] (bcm2836_arm_irqchip_handle_ipi+0xa8/0xc8) [ 260.218146] [<80675f10>] (bcm2836_arm_irqchip_handle_ipi) from [<80184db4>] (generic_handle_irq+0x44/0x54) [ 260.234163] r7:00000001 r6:00000000 r5:00000000 r4:80e90d10 [ 260.243229] [<80184d70>] (generic_handle_irq) from [<80185514>] (__handle_domain_irq+0x6c/0xc4) [ 260.258182] [<801854a8>] (__handle_domain_irq) from [<801012c8>] (bcm2836_arm_irqchip_handle_irq+0x60/0x64) [ 260.274535] r9:81562000 r8:00000001 r7:81563f64 r6:ffffffff r5:60000013 r4:801088c4 [ 260.282803] SMP: failed to stop secondary CPUs [ 260.288405] [<[[ 2n0.2960e0]p---[ -nd ternelipan c - not syncing Fataleexception-in in+errupt ]-)- [ 260.308653] Exception stack(0x81563f30 to 0x81563f78)
I eventually decided I wasn't getting anywhere with troubleshooting, so I swapped back to the existing DSM (which at least stays up on the order of days, instead of minutes). The original DSM is back in place and is still online as of writing this blog post. Presumably if it goes down again a reboot will work to get it running again.
Since we've seen similar behavior in two DSMs at Marshall (and since the replacement DSM wasn't doing things like this while I was setting it up) I'm wondering if it's something to do with power after all. Or maybe a problem that only occurs when sensors/ubiquiti/etc are plugged in?
The time-height-plot web-visualization tool and its API have been updated to support processing algorithms besides 5-minute consensus:
- http://datavis.eol.ucar.edu/time-height-plot/LOTOS2021/iss1/30-minute-consensus
- http://datavis.eol.ucar.edu/time-height-plot/LOTOS2021/iss4/nima
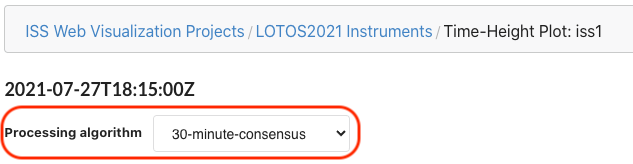
For profilers that have more than one processing algorithm, eg. ISS1 with 5- and 30-minute consensus periods, the processing algorithm can be selected in the project's list of profilers:

Or via a dropdown menu above the chart:
Force-refreshing the page in the browser may be required for changes to take effect:
In most browsers on PC and Mac, you can perform a simple action to force a hard refresh. Hold down the Shift key on your keyboard and click on the reload icon on your browser’s toolbar.
https://www.howtogeek.com/672607/how-to-hard-refresh-your-web-browser-to-bypass-your-cache/
5- and 30-minute consensus data has also been loaded for historical projects, CHEESEHEAD, PECAN and SAVANT; as well as the ongoing FL_TESTS project that has a 449MHz profiler running at Foothills.
Noticed this afternoon that the DSM was down again. Ubiquiti was up, so presumably a DSM problem. I decided that since this keeps happening it's time to replace the entire DSM, so I started configuring one of the ones in the wind tunnel as tt so I can swap it out. Hopefully I'll be able to finish that Monday or Tuesday.
After the thunderstorms died down I went out to Marshall to reboot, so at least it could collect data over the weekend. When I got there I couldn't log in over ethernet or the console, so rebooted. After reboot it's back on the net and is still up Saturday morning.
After seeing Jacquie's blog post yesterday about no data I did some troubleshooting (see comment on Jacquie's post) but only succeeded in taking the DSM off the net entirely. I went out to Marshall to reboot it twice, each time bringing it up briefly but then it would go down again. Went back for a longer visit in the afternoon with Gary (thanks Gary!) to do more troubleshooting.
The DSM always came up after reboot, but wouldn't stay up very long. When we were logged in over the console, we could see kernel error messages before it went down. In one case we saw that nidas was running correctly just after rebooting, but eventually stopped (couldn't find anything relevant in the logs) and had to be restarted with dup. Seems like this is the same problem as what Jacquie noted originally. We also sometimes saw error messages about I/O errors trying to access the usb stick when starting nidas or using the lsu command.
We did some testing of the pio command, and it seems that using pio -v to see the current state sometimes turns power off to some or all of the ports. pio can turn off power to bank1 (powering the switch) and 28v (powering the ubiquiti), either of which would take the dsm off the net when you're logged in remotely. Until we can fix the pio -v behavior we unplugged the cable between the autoconfig board and the power panel, so using pio -v shouldn't be able to turn off power to bank1 or 28v.
We also noticed that it was taking a very long time for the dsm to get the correct time after reboot (sometimes like half an hour). It turns out that pps0 wasn't giving any data, it was on pps1 instead. We tried modifying chrony.conf and disconnecting the pps, but neither seemed to do much (Gary, you can add stuff if you remember more of the details).
Eventually we decided that the DSM wasn't reliable enough to leave up because of all the kernel errors, so we replaced the pi with one from a spare DSM we brought. That worked, and Gary made some updates remotely:
I had to install xinetd on the DSM to get check_mk to work from snoopy, and then nagios noticed that the USB filesystem was missing. So I decided to upgrade the whole DSM before rebooting it, and it turns out there were quite a few updates. The USB came back and has not failed all night, but it's good that it's getting checked now.
I also modified the chrony.conf to add the iburst option to the tardis server line. That makes chrony sync much faster to the network NTP server, and it makes sense to rely on that since the PPS is not working.
Finally, I discovered a bug with the data_stats and dashbaoard, where the data_stats will just keep counting up from 2010 if the system time was wrong when data_stats started. The quick workaround was to restart the json_data_stats service after the system time was correct.
The DSM went down again at 8:20 this morning. Dan is at Marshall this morning and rebooted the DSM around 11:30, which brought it back on the net. I looked through the logs and it seems like this time the DSM was collecting data while it was off the net, so it may have just been an ethernet issue. DSM is back off the net now though, about 10 minutes after Dan rebooted it.
Since the DSM clearly still isn't reliable, I'm thinking the next step would be setting up a whole new dsm + SD card as tt when I'm in the office tomorrow...
This afternoon I launched a sounding at 14:24 MDT (2024 UTC). All went well except that I got an error from the sounding software saying "Surface observations reading failed" and I was forced to enter surface values manually. Of course since we don't have surface met here I used sounding data instead, but first I had to toggle "Full control" to "Release control" on the sounding software in order to get past the popup window requiring me to enter surface values. I had to estimate surface wind speed and direction from the WXT at MISS. After that all worked as expected.
The 1st helium tank is just about empty, as I took about all of the rest of it to fill the balloon to 28 cu ft.
I also noticed that the most recent lidar plots on both the field catalog and ISS1 web plots page were from 1649 UTC (10:49 MDT) today. Nagios is showing errors that may be related to this as well. Perhaps this is due to a change in scan strategy to mostly fixed stares and PPI's or something that Isabel is working on in her hawkeye plotting scripts?
Visited LOTOS test site to swap out all three EC150s for calibration.
| Height | Original (Asset Panda S/N) | Installed 4 Aug 21 (Asset Panda S/N) |
|---|---|---|
| 27m | 10316 | 10311 |
| 17m | 10303 | 10327 |
| 7m | 10322 | 10314 |
- Additional Maintenance
- Static Dissipater at top of tower was bent 180 degrees towards the ground upon arrival. Reset to the proper position.
- Slight releveling
- Tightening of guy wires
DSM network issue continues, but Isabel is actively working on solving that.
Checked sensor time series since Jul 20 2021
- NCharts stopped reporting 2 August 16:12:30
- DSM dashboard stopped reporting 2 August 22:30:40
QC Notes
- There is a data gap 23-24 July. Data from a number of sensors spike downward before disappearing. These need to be filtered.
- Heavy rains July 30-31
- TRH - ok
- P - ok
- Pirga
- Pirga.7m is offset from P.7m by +6mb (Pirga higher).
- Pirga.27m measures too high. Pirga.27m > Pirga.17m.
- Tirga
- Tmote measures wildly divergent values compared to all T measurements
- Radiometer - ok
- Rpile.in [-150, 0], Rpile.out [-25, 125] W/m2
- QC Note: Rpile.out - Filter spike at 30 July, 14:12:30
- Rsw.in [-7, 1200], Rsw.out [-1, 225] W/m2
- Tcase - ok
- Wetness - ok
- Soils
- Gsoil - ok [-39, 55]W/m2
- Lamdasoil
- QC Note - Discontinuity after data gap on 24 July - values double from 0.2 W/m to 0.45.
- Qsoil
- QC Note - Same as Lamdasoil - values jump from near zero to 0.1 %Vol
- Tau63 - ok overall
- QC Note - Same as Lamdasoil - there is a discontinuity after data gap.
- Tsoil - ok overall
- QC Note - spikes at all levels July 26 - Aug 2.
- Sonic - ok
- co2/h2o
- 27m Back online
- QC Notes
- A few h2o/co2 spikes July 21-25 to filter that may not get captured by the wetness sensor.
- Persistent bias: co2.7m > co2.27m > co2.17m
- Tcase - ok
- Batteries
- Vheat - ok
- iload - ok. [1.85 - 2] A
- icharge - ok. [-.175 to 0.014] A
- Vbatt - ok
- l3mote - ok. ~ 50 mA (minus spikes).
- lmote - ok ~15 mA (minus spikes).
- Vcharge - ~27.9 V
- Rfan - ok [5400 - 5650] rpm