
Arrived: 10:12am MDT
Departed: 1:45pm MDT
Ned and I did a couple of chores on this visit. First, we fixed the 43M sonic. It seemed to be the port on the Emerald Card. Switched 43M sonic from port16 to port20. Ned updated the xml. Second, we replaced two 15M cable from 43M Licor with a 30M cable. When we did this we noticed interrupts on the dsm. Having unplugged the battery charger for the laptop to talk with dsm, we plugged the charger back in and the dsm didn't give as much interrupts. [shrugging] Will keep an eye on this odd situation. Third, we clean all three Licors. Fourth, took guywire tensions.
Want to mention that there is a 2M tower just 15' South of the Turbulence Tower. WTF?
Also, there are no more ports on ethernet switch or 120AC power.
Ned noticed a drop out of data from 43 meters on Jul 10.
http://www.eol.ucar.edu/isf/projects/BEACHON_SRM/isfs/qcdata/plots/20110711/plots_all.shtml
I logged into the manitou data system on Jul 13, and tried to resurrect it.
I tried rserial, minicom and powering the sonic off and on:
eio 16 0
eio 16 1
rs 16
Got nutt'in
The licor is working. We compute its mean and higher moments in
combination with the sonic data, so that if we don't have sonic
data then we see no co2, co2'co2', w'co2', etc.
We do see the status values from the licor, and I rserial'd to
it and see that it's working.
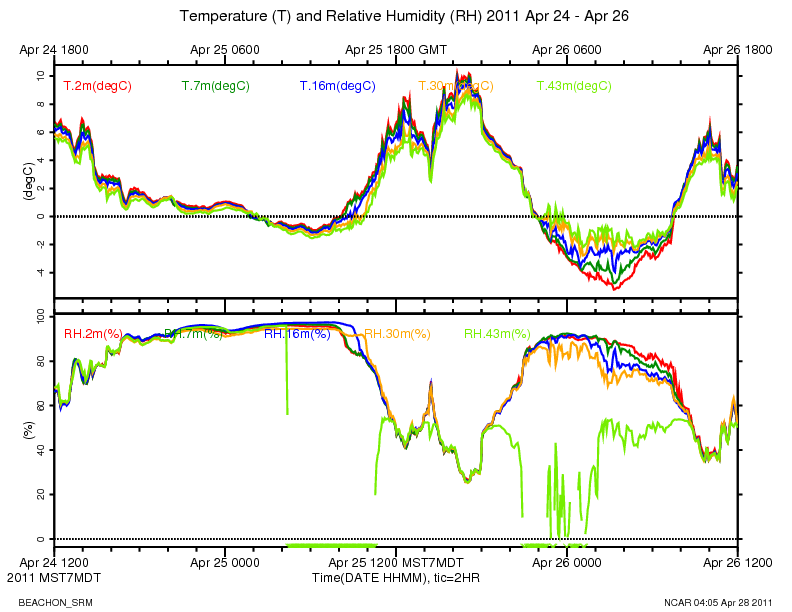
RH at 43m has been bad for a while. Looking back through the plots, looks like it failed the night of Apr 25 during a period of near 100% RH.
http://www.eol.ucar.edu/isf/projects/BEACHON_SRM/isfs/qcdata/plots/20110425/trh_20110425.png
{kind=link}
The plot of GPSdiff_max for May 22, 2011 shows a maximum value of around 25 seconds between 11:05 and 17:00 UTC, indicating something went haywire with the data collection during those times.
Looking at the downloaded data, it appears that data stopped coming in on the Diamond serial ports at 11:05, and resumed at 17:00. There is not a large gap in data from the 3 sensors that are sampled on the Viper serial ports, but they show large time tag delta-Ts, followed by many small delta-Ts, symptomatic of the system getting behind and having to do major buffering. Perhaps a "storm" of interrupts from the Diamond that finally cleared up? Moisture somewhere?
I don't have time to look into it at this time, but here are some dumps of data around the problem.
data_stats /scr/isfs/projects/BEACHON_SRM/raw_data/manitou_20110522_000000.dat
2011-05-24,16:56:30|INFO|opening: /scr/isfs/projects/BEACHON_SRM/raw_data/manitou_20110522_000000.dat
EOFException: /scr/isfs/projects/BEACHON_SRM/raw_data/manitou_20110522_000000.dat: open: EOF
sensor dsm sampid nsamps |------- start -------| |------ end -----| rate minMaxDT(sec) minMaxLen
1 20 39901 2011 05 22 00:00:00.998 05 22 11:05:01.461 1.00 0.336 1.643 19 19
1 30 84632 2011 05 22 00:00:00.571 05 22 11:59:59.719 1.96 0.042 26.076 51 73
1 100 843525 2011 05 22 00:00:00.160 05 22 11:59:59.944 19.53 -2.052 27.951 12 16
1 110 415176 2011 05 22 00:00:00.113 05 22 11:59:59.959 9.61 -2.016 28.058 39 87
1 120 41042 2011 05 22 00:00:00.185 05 22 11:05:01.388 1.03 0.294 1.643 29 31
1 200 798028 2011 05 22 00:00:00.166 05 22 11:05:01.873 20.00 0.005 0.596 12 12
1 220 40687 2011 05 22 00:00:00.791 05 22 11:05:01.158 1.02 0.357 1.604 28 29
1 300 798048 2011 05 22 00:00:00.168 05 22 11:05:01.884 20.00 0.002 0.585 12 12
1 310 399023 2011 05 22 00:00:00.000 05 22 11:05:01.841 10.00 0.042 0.454 44 49
1 320 40488 2011 05 22 00:00:00.233 05 22 11:05:01.428 1.01 0.356 1.613 28 29
1 330 7981 2011 05 21 23:59:55.213 05 22 11:04:55.250 0.20 4.415 5.586 49 60
1 400 798041 2011 05 22 00:00:00.005 05 22 11:05:01.883 20.00 0.001 0.591 12 12
1 420 40772 2011 05 22 00:00:00.328 05 22 11:05:01.192 1.02 0.344 1.614 29 30
1 500 798042 2011 05 22 00:00:00.171 05 22 11:05:01.913 20.00 0.002 0.603 12 12
1 510 399020 2011 05 22 00:00:00.007 05 22 11:05:01.814 10.00 0.037 0.436 44 49
1 520 40747 2011 05 22 00:00:00.342 05 22 11:05:01.149 1.02 0.372 1.588 27 29
[maclean@porter ~]$ data_stats /scr/isfs/projects/BEACHON_SRM/raw_data/manitou_20110522_120000.dat
2011-05-24,16:57:04|INFO|opening: /scr/isfs/projects/BEACHON_SRM/raw_data/manitou_20110522_120000.dat
EOFException: /scr/isfs/projects/BEACHON_SRM/raw_data/manitou_20110522_120000.dat: open: EOF
sensor dsm sampid nsamps |------- start -------| |------ end -----| rate minMaxDT(sec) minMaxLen
1 20 25156 2011 05 22 17:00:47.215 05 22 23:59:59.960 1.00 0.019 1.371 19 29
1 30 73288 2011 05 22 12:00:25.745 05 22 23:59:59.741 1.70 0.104 26.116 51 73
1 100 750227 2011 05 22 12:00:28.065 05 22 23:59:59.959 17.38 -2.052 27.951 12 16
1 110 337790 2011 05 22 12:00:28.120 05 22 23:59:59.922 7.82 -2.016 28.058 17 69
1 120 25895 2011 05 22 17:00:47.289 05 22 23:59:59.553 1.03 0.029 1.756 29 38
1 200 502634 2011 05 22 17:01:05.737 05 22 23:59:59.999 20.00 0.000 2.518 2 466
1 220 25715 2011 05 22 17:00:47.290 05 22 23:59:59.392 1.02 0.028 1.594 28 39
1 300 502351 2011 05 22 17:01:20.419 05 22 23:59:59.968 20.00 0.000 2.538 2 465
1 310 251531 2011 05 22 17:00:47.284 05 22 23:59:59.926 10.00 0.050 0.154 44 66
1 320 25590 2011 05 22 17:00:47.291 05 22 23:59:59.734 1.02 0.028 1.315 28 39
1 330 5032 2011 05 22 11:05:00.251 05 22 23:59:50.264 0.11 0.061 21347.049 6 61
1 400 502055 2011 05 22 17:01:35.059 05 22 23:59:59.987 20.00 0.001 2.508 3 466
1 420 25769 2011 05 22 17:00:47.292 05 22 23:59:59.864 1.02 0.029 1.523 29 37
1 500 502936 2011 05 22 17:00:45.341 05 22 23:59:59.998 19.99 0.003 4.123 12 466
1 510 251530 2011 05 22 11:05:01.916 05 22 23:59:59.963 5.41 0.027 21345.401 43 50
1 520 25730 2011 05 22 17:00:47.294 05 22 23:59:59.423 1.02 0.028 1.631 26 39
Data kept coming in on the Viper serial ports (ids=30,100,110, GPS, sonic and licor at 2m), but had time tag issues, apparently because buffers filled up. Here's a snippet of the 2m sonic data in hex, showing a 28 second time tag jump, but no skip in the sonic sequence (byte 9: f8,f9,fa,fb,fc, etc)
2011 05 22 11:05:53.8243 0.05004 12 20 06 0b 03 39 ff 6e e8 f5 0f 55 aa 2011 05 22 11:05:53.8743 0.04997 12 6a 06 0f 03 1b ff 6a e8 f6 0f 55 aa 2011 05 22 11:05:53.9243 0.05002 12 bf 05 b1 02 de fe 69 e8 f7 0f 55 aa 2011 05 22 11:05:53.9743 0.04998 12 4d 05 cb 02 d0 fe 6e e8 f8 0f 55 aa 2011 05 22 11:06:21.9147 27.94 12 35 05 d6 02 df fe 71 e8 f9 0f 55 aa 2011 05 22 11:06:21.9272 0.0125 12 03 06 7f 03 30 ff 6f e8 fa 0f 55 aa 2011 05 22 11:06:21.9397 0.0125 12 32 06 7f 03 98 ff 65 e8 fb 0f 55 aa 2011 05 22 11:06:21.9522 0.0125 12 46 05 59 02 35 ff 6d e8 fc 0f 55 aa 2011 05 22 11:06:21.9647 0.0125 12 83 05 1a 03 c3 fe 75 e8 fd 0f 55 aa
After the gap, the 0.0125 dTs result from unpacking multiple samples from a buffer, where the code computes a dT = 10 bits/byte / (9600 bits/sec) * 12 bytes/sample = 0.0125 sec/sample
I see no indication of a problem in the system logs, or any weird clock adjustments in the NTP loopstats,peerstats.
Arrived: 10:30am MDT
Departed: 11:20am MDT
Kurt and I installed three LiCors on turbulence tower at heights of 2M, 15M and 45M. TRHs were installed on all levels. New GPS was added and old Garmin was removed.
LiCor heights:
2M-1166
15M-1163
45M-1164
Apr 12, 11:32 am
The output format and reporting rate of the 3 Licor 7500s that were re-installed today had been reset during the calibration procedure to generate verbose output, with labels. To save archive space, we configure the units for a terse output, without labels, at 10 Hz.
To setup the Licors for the format that our data system expects, do the following from the data system login prompt:
- shut down the data process
adn - run minicom on the Licor port (ttyS2=2m, ttyS7=7m, ttyS11=16m, ttyS14=30m, ttyS17=43m)
minicom ttyS2 - If the baud rate agrees with minicom (9600) you should see the default Licor output
- Send a break character, by doing "control-A f" from minicom
ctrl-Af - Send these strings to the Licor:
(Outputs (RS232 (EOL "0A") (Labels FALSE) (DiagRec FALSE) (Ndx FALSE) (Aux FALSE) (Cooler FALSE) (CO2Raw TRUE) (CO2D TRUE) (H2ORaw TRUE) (H2OD TRUE) (Temp TRUE) (Pres TRUE) (DiagVal TRUE))) (Outputs (BW 10) (Delay 0) (RS232 (Freq 10.0) (Baud 9600))) (Outputs (Dac1 (Source NONE)(Zero 0)(Full 5)) (Dac2 (Source NONE)(Zero 0)(Full 5)))
- You won't see much output, perhaps just 1 column of digits on the right-hand-side, since the Licor is sending just a line-feed termination and no carriage-return. You can turn on line wrap in minicom, with "control-A w" to see the data stream wrap from side to side:
ctrl-Aw - Exit minicom with control-A q
ctrl-Aq - restart the data process:
aup - check the Licor data with rserial. It may take 30 seconds or so for the data system to open the port. During that time rserial will report an error about not finding the sensor. Eventually it should work.
rs 2 - The data should look like:
248\t0.06460\t12.4193\t0.01218\t81.586\t16.10\t76.1\t\n 248\t0.06462\t12.4179\t0.01207\t81.459\t16.11\t76.1\t\n
- Exit rserial with control-D
ctrl-d
Calibration process for LiCors 7500s. I calibrated all five LiCors. Calibration included post cal, desiccant change, spot check, zero/span. I used N2 tank which went through a scrubber of Ascarite II and Drierite to give the zero for both CO2 and H20.
Post-Cal conditions were checking zeros, span and dew point. Spans included for CO2 were a bottle of 394.611ppm and 378.867ppm. For H2O I used the Thunder Scientific, humidity chamber, set at 25C at 80%RH. Dew point was equal to 21.31C.
Zero Post-Conditions: Pressure 85.04kPa, Temp=27.3C
Sensor ID |
CO2(umol/mol) |
H2O(mmol/mol) |
CO2 Coeff.(zero/span) |
H2O Coeff.(zero/span) |
|---|---|---|---|---|
0813 |
0.08 |
1.11 |
N/A |
N/A |
1166 |
6.58 |
-1.59 |
0.8896/1.0051 |
0.8583/0.9969 |
1163 |
-7.90 |
0.24 |
0.8709/1.0082 |
0.8510/1.0229 |
1167 |
-3.23 |
-0.15 |
0.8770/1.0207 |
0.8732/0.9986 |
1164 |
-10.80 |
0.43 |
0.8902/1.0233 |
0.8635/1.0008 |
Span Post-Conditions: Column2 is standard 394.611ppm; Column3 is standard 378.867ppm; Column4 is dew point standard 21.31C
Sensor ID |
CO2(ppm) |
CO2(ppm) |
H20(C) |
|
|---|---|---|---|---|
0813 |
----------------------- |
-------------------------- |
-------------------- |
|
1166 |
400.83 |
387.48 |
21.16C |
|
1163 |
389.02 |
373.09 |
22.07 |
|
1167 |
398.17 |
382.72 |
20.93 |
|
1164 |
389.60 |
373.81 |
21.82 |
|
Quick Check after desiccant was changed and ran for overnight. Pressure 82.62kPa, Temp 24.33C
Sensor ID |
CO2(ppm) |
H2O(C) |
CO2(378.867ppm) |
|---|---|---|---|
0813 |
--------------- |
-------------- |
-------------------------- |
1166 |
6.61 |
------------- |
------------------------- |
1163 |
-6.05 |
0.41 |
-------------------------- |
1167 |
-2.35 |
------------- |
--------------------------- |
1164 |
-6.61 |
0.43 |
380.54 |
Zero Calibration: CO2 and H20 were set to zero value.
Sensor ID |
CO2(ppm) |
H20(ppm) |
CO2 Coeff. |
H20 Coeff. |
|---|---|---|---|---|
0813 |
-0.01 |
0.00 |
0.9752 |
0.7374 |
1166 |
-0.03 |
0.00 |
0.8909 |
0.8605 |
1163 |
-0.01 |
0.00 |
0.8698 |
0.8532 |
1167 |
0.01 |
0.00 |
0.8766 |
0.8749 |
1164 |
0.01 |
0.00 |
0.8889 |
0.8662 |
Span Calibration: CO2 was spanned to 394.611ppm; H20 was spanned to dew point 21.31C.
Sensor ID |
CO2(ppm) |
H20(ppm) |
CO2 Coeff. |
H2O Coeff. |
|---|---|---|---|---|
0813 |
394.43 |
21.43 |
0.9936 |
1.0380 |
1166 |
394.43 |
21.44 |
1.0052 |
1.0497 |
1163 |
394.65 |
21.45 |
0.9950 |
1.0211 |
1167 |
394.84 |
21.41 |
1.0049 |
1.0258 |
1164 |
394.56 |
21.42 |
1.0008 |
1.0206 |
The TRH sensors went through a post cal check before re-calibration.
Here are the results.
Temperature: Tested over the range of -30 to 30. It has been almost 1 year since these sensors were calibrated 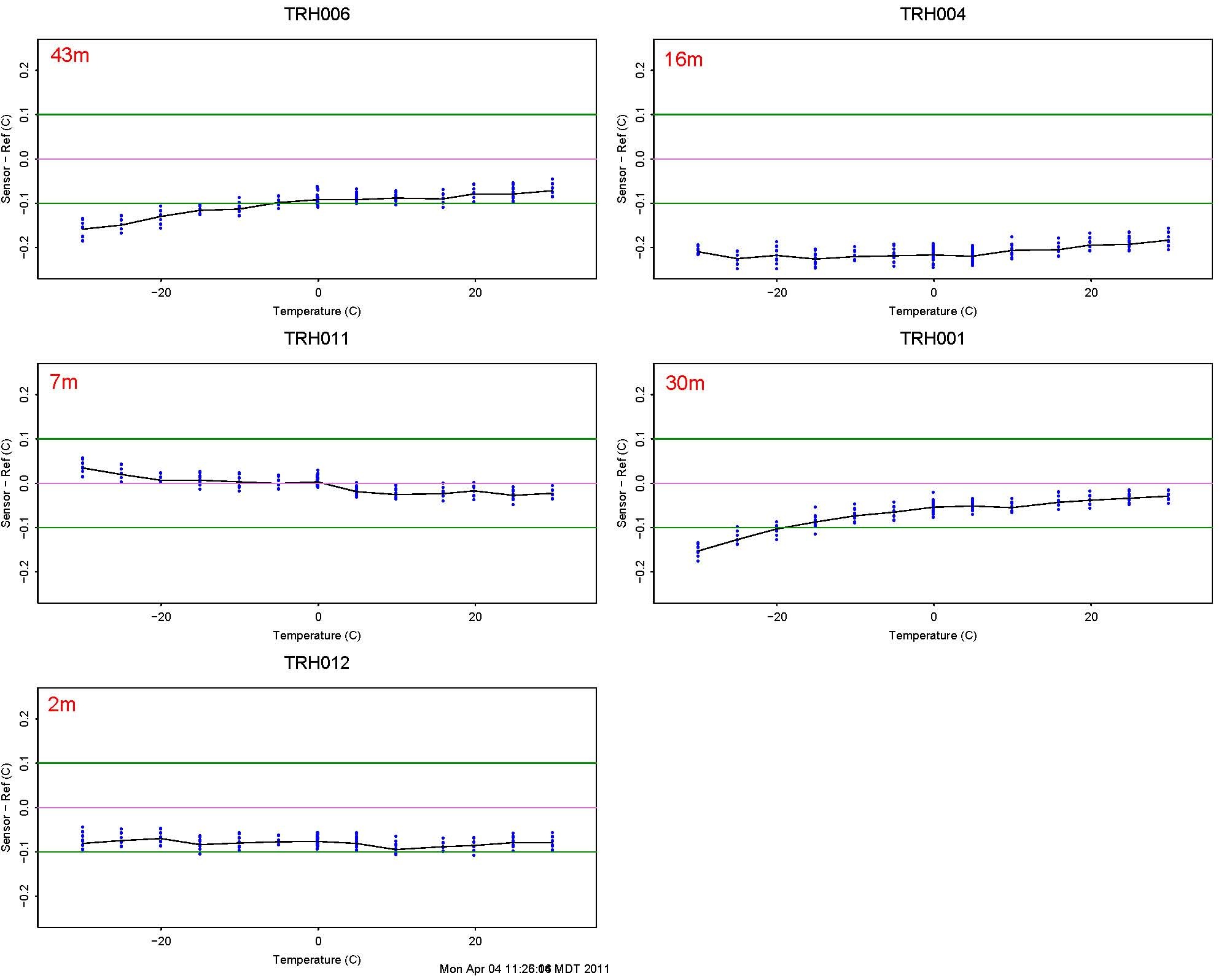
Relative Humidity: Tested over 10% to 90% at temperatures 25, 10, -3 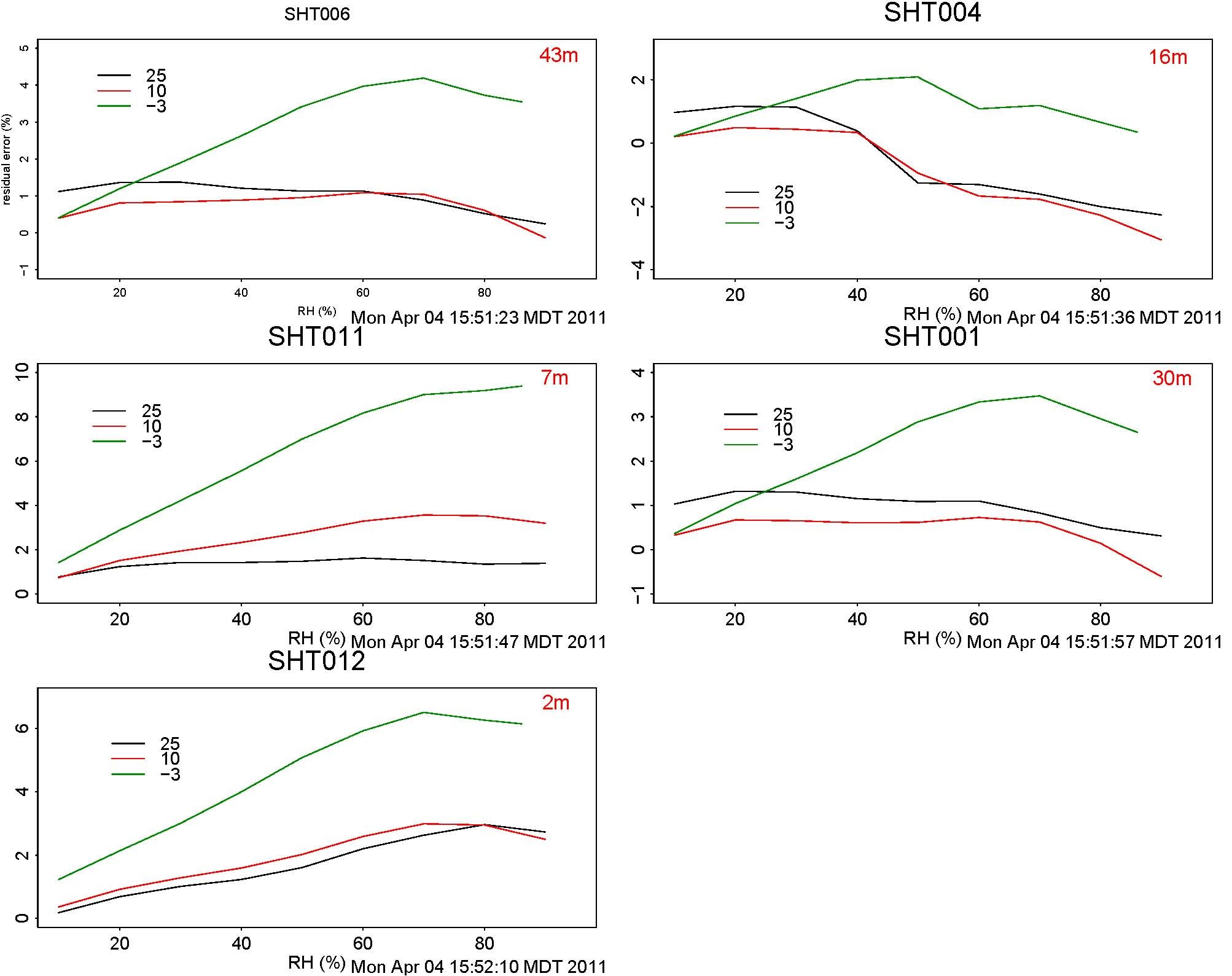
The Licor 7500 and TRH sensors were removed on 3/29. They will be re-calibrated and re-installed in about 2 weeks.
So sorry. This is a redundant log entry. First entry was in the main Manitou Log entry page.
Attendees: Chris, Kurt and Ned.
Arrived at 11:25am
Departed at 1:15pm
Removed LiCors and TRHs at all heights. The LiCors were at the following heights.
2m: s/n 1163
7m: s/n 1166
15m: s/n 1167
45m: s/n 1164
We unplugged main power to all LiCors in the battery boxes. Replaced both outside GFI outlets. Both outlets were blown. Power back to both outlets. Beacon back on.
Installed the latest version of nidas (revision 5771M) today, with the new process running at 19:49 UTC.
The new nidas has some improvements in the serial handling efficiency. Don't see any effect on the number of "spurious interrupts" though.
Also restarted ntp daemon. Added a "server ral" entry in /etc/ntp.conf so that we can compare our local GPS time source with the ral server.
ntpq -p shows good agreement (-8.285 millisecond offset) with the ral server:
ntpq -p
remote refid st t when poll reach delay offset jitter
==============================================================================
xral 208.75.88.4 3 u 7 64 377 0.368 -8.285 1.249
oGPS_NMEA(0) .GPS. 2 l 15 16 377 0.000 -0.028 0.031
Querying the ral ntp server, with ntpq -p ral shows that it has offsets with its servers, probably related to the big delays over its wifi connection:
ntpq -p ral
remote refid st t when poll reach delay offset jitter
==============================================================================
+64.6.144.6 128.252.19.1 2 u 300 1024 177 43.800 -32.309 12.143
*208.75.88.4 192.12.19.20 2 u 997 1024 377 56.151 16.212 0.321
+64.73.32.134 192.5.41.41 2 u 502 1024 377 42.897 7.307 110.558
Later, Oct 16, 15:24 MDT, saw smaller offsets all around:
root@manitou root# ntpq -p
remote refid st t when poll reach delay offset jitter
==============================================================================
xral 208.75.88.4 3 u 39 64 377 0.354 1.108 0.390
oGPS_NMEA(0) .GPS. 2 l - 16 377 0.000 0.003 0.031
root@manitou root# ntpq -p ral
remote refid st t when poll reach delay offset jitter
==============================================================================
+64.6.144.6 128.252.19.1 2 u 135 1024 373 41.912 0.464 74.268
*208.75.88.4 192.12.19.20 2 u 840 1024 357 56.112 2.963 1.735
+64.73.32.134 192.36.143.150 2 u 317 1024 377 39.507 1.365 64.459
Data from the 7m TRH has been intermittent for more than a month.
Here's a typical dropout, where the unit quits reporting, then 15
hours later comes alive, with startup messages:
2010 10 02 14:07:54.4656 0 40 \x00\x00\r Sensor ID16 data rate: 1 (secs)\n 2010 10 03 05:28:49.2103 5.525e+04 29 \rcalibration coefficients:\r\n 2010 10 03 05:28:49.2517 0.04144 21 Ta0 = -4.042937E+1\r\n 2010 10 03 05:28:49.2827 0.03095 21 Ta1 = 1.022852E-2\r\n 2010 10 03 05:28:49.3134 0.0307 21 Ta2 = -2.096747E-8\r\n 2010 10 03 05:28:49.3445 0.0311 21 Ha0 = -1.479133E+0\r\n 2010 10 03 05:28:49.3773 0.03286 21 Ha1 = 3.554063E-2\r\n 2010 10 03 05:28:49.4057 0.02836 21 Ha2 = -1.382833E-6\r\n 2010 10 03 05:28:49.4390 0.03329 21 Ha3 = 3.354407E-2\r\n 2010 10 03 05:28:49.4693 0.03031 21 Ha4 = 3.666422E-5\r\n 2010 10 03 05:28:49.8050 0.3357 29 TRH16 4.91 94.96 4474 3057\r\n
Email from Ned:
the TRH at 7m now seems to be re-appearing during the night time and then at about 8am it drops out again...
http://www.eol.ucar.edu/isf/projects/BEACHON_SRM/isfs/qcdata/plots/20101001/Tprof_20101001.png
{kind=link}
My guess is that it is a power problem, either in the cable, or corrosion in the unit. This unit and
cable was replaced on 7/22. The problem before was different, looking like a RS232 problem, where
I don't think we saw the bootup messages we're seeing now. https://wiki.ucar.edu/x/vBWdAw
7/22/10
re-tensioned all guy wires using transits to plumb tower.
replaced 7m and 15m trh cables, as well as 7m trh sensor
The Licor 7500 at 2m has not been reporting for a while.
Looking at /proc/tty/driver/serial for port 2 indicates that no characters have been received since the last reboot. As of Jul 18 the system uptime is 19 days.
Did "rs 2" to talk to the port. After sending carriage a return the 7500 responds with
^M(Error (Received TRUE))\n
So, it is alive and responding, just not sending data. Sent it a configuration command, setting the BW and RS232 parameters, which got it going again:
(Outputs (BW 10) (RS232 (Freq 10.0) (Baud 9600)))
It responded with the following and then started streaming data:
(Ack (Received TRUE)(Val 0))
Looks like it didn't come up in continuous reporting mode for some reason - either after a power outage, or after receiving some glitch characters on its input.
There may be a better command to get it going again once it has been interrupted.
I just knew from prior experience that the above works. Probably just a "(Outputs)" or
"(Outputs (BW 10))" would also work.
The turbulence tower data system clock was behind by 1 second from May 4 to Jun 11. If sub-second absolute time-tag accuracy of the data samples is a not a concern, then you can ignore this log message. Otherwise, here are the gory details...
The data system was replaced on the turbulence tower on May 4.
The new system is running a new version (4.2.6p1) of the NTP (network time protocol) service. NTP on the data system is configured to use the attached GPS (Garmin 25-HVS) as a reference clock. NTP reads the NMEA messages from the GPS, which contain the absolute time, at a precision of a second, and it monitors the PPS (pulse-per-second) signal from the GPS. The leading edge of the PPS has approximate 1 microsecond absolute accuracy. Using the two inputs, NTP can condition the embedded data system clock to an absolute accuracy which is typically better than 300 microseconds.
The NMEA messages from the 25-HVS have a roughly 0.4 - 0.8 second lag, meaning the NMEA message for 00:00:00 arrives at the data system between 0.4 and 0.8 seconds late, at sometime after 00:00:00.4
The new version of NTP must be passed a parameter, known as "time2", specifying the approximate lag in seconds of the NMEA messages. If the value is left as the default, 0.0, then NTP assigns the time of a PPS with the time of the most recently received NMEA message, which results in a Linux system clock that is exactly 1 second behind absolute time.
On Jun 11 I detected this issue when fiddling with a data system in the FLAB parking lot, where I also had access to a NTP server on the network.
Here's the last 2 points of data from the GPS on the old system on May 4 at 18:33:34 UTC. There is a gap of 3848 seconds while the data system was swapped out, and the first 2 GPS data points from the new system at 19:37:42.
data_dump -i 1,30 -A manitou_20100504_120000.bz2 | more ... 2010 05 04 18:33:34.7163 1.127 73 $GPRMC,183334,A,3906.0321,N,10506.3310,W,000.0,289.2,040510,010.5,E*60\r\n 2010 05 04 18:33:34.8746 0.1583 72 $GPGGA,183334,3906.0321,N,10506.3310,W,1,06,1.7,2396.4,M,-21.3,M,,*46\r\n 2010 05 04 19:37:42.3816 3848 73 $GPRMC,193743,A,3906.0352,N,10506.3241,W,000.0,000.0,040510,010.5,E*65\r\n 2010 05 04 19:37:42.5430 0.1614 72 $GPGGA,193743,3906.0352,N,10506.3241,W,1,06,4.2,2391.6,M,-21.3,M,,*47\r\n
The absolute time in the NMEA messages is the HHMMSS field between the commas after $GPRMC or $GPGGA. The $GPRMC NMEA message for 183334 was received and timetagged with a system clock value of 18:33:34.7163, which is a typical lag of .7163 seconds. After the gap, the first NMEA message with a value 193743 was assigned a timetag of 19:37:42.3816, indicating that the system clock was 1 second early.
On Jun 11 the value of the "time2" parameter was changed to 0.8 seconds and ntp restarted on the data system. By looking at the data_dump it appears that NTP corrected the system clock around 20:53:43 UTC.
2010 06 11 20:53:42.1074 0.9465 73 $GPRMC,205343,A,3906.0359,N,10506.3337,W,000.0,206.3,110610,010.5,E*66\r\n 2010 06 11 20:53:42.2698 0.1624 72 $GPGGA,205343,3906.0359,N,10506.3337,W,1,06,1.6,2398.5,M,-21.3,M,,*4F\r\n 2010 06 11 20:53:44.7440 2.474 73 $GPRMC,205344,A,3906.0358,N,10506.3338,W,000.0,206.3,110610,010.5,E*6F\r\n 2010 06 11 20:53:44.9072 0.1632 72 $GPGGA,205344,3906.0358,N,10506.3338,W,1,06,1.6,2398.7,M,-21.3,M,,*44\r\n
NTP was adjusting the Linux system clock for a minute or two prior to 20:53:43 and so the accuracy of those timetags is unknown. For example, the 20 Hz sonic data shows a jump forward of 1.598 seconds at this time. It looks like NTP and the Linux kernel first slowed the the clock down for a period of time and then made a ~1.55 second jump forward.
data_dump -i 1,100 -H ../raw_data/manitou_20100611_120000.dat | more ... 2010 06 11 20:53:42.7157 0.05111 12 48 00 26 02 fc 01 d7 09 d0 0f 55 aa 2010 06 11 20:53:42.7647 0.04894 12 55 ff 9a 01 64 02 e8 09 d1 0f 55 aa 2010 06 11 20:53:44.3625 1.598 12 8a fe f0 01 45 02 53 0a d2 0f 55 aa 2010 06 11 20:53:44.4117 0.04916 12 d9 ff 35 02 0d 02 8e 0a d3 0f 55 aa 2010 06 11 20:53:44.4631 0.0514 12 37 01 42 02 d9 01 b9 0a d4 0f 55 aa
After the correction on Jun 11 the absolute accuracy of the data system clock should be generally better than 300 microseconds.
Much ado about nothing...